复刻 @影视飓风 同款运营数据面板
前不久刷到影视飓风的运营数据看板,可以每隔 15min 自动获取账号所有平台的数据,实时更新可视化的数据仪表盘,可把本运营牛马羡慕坏了。
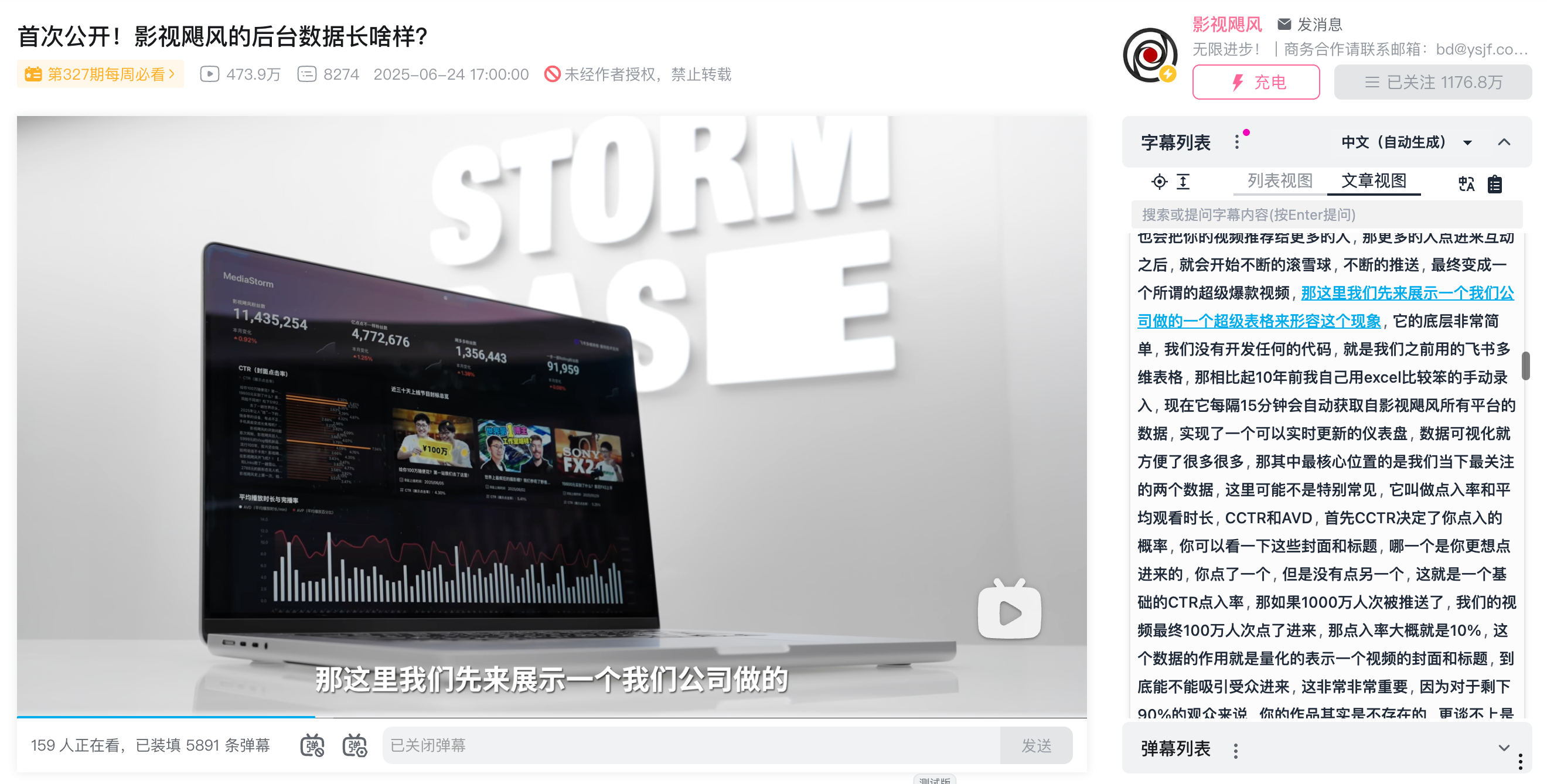
虽说咱也整了俩小玩意帮我看 b 站数据和评论,能推送到飞书提醒我处理,但是前司 5 个账号的多平台粉丝数还是本人手动收录的……要求是每月录入一次,频次一般当时就没折腾(主要还是加班没空🚬)。
看到影视飓风的示例,想着终于可以抄作业了,顺藤摸瓜找到了飞书的多维表格模板,但很不幸这只是个最终的展示物,真正可用的「自动获取数据」在飞书官方搭建服务售卖 ¥4999/场景。
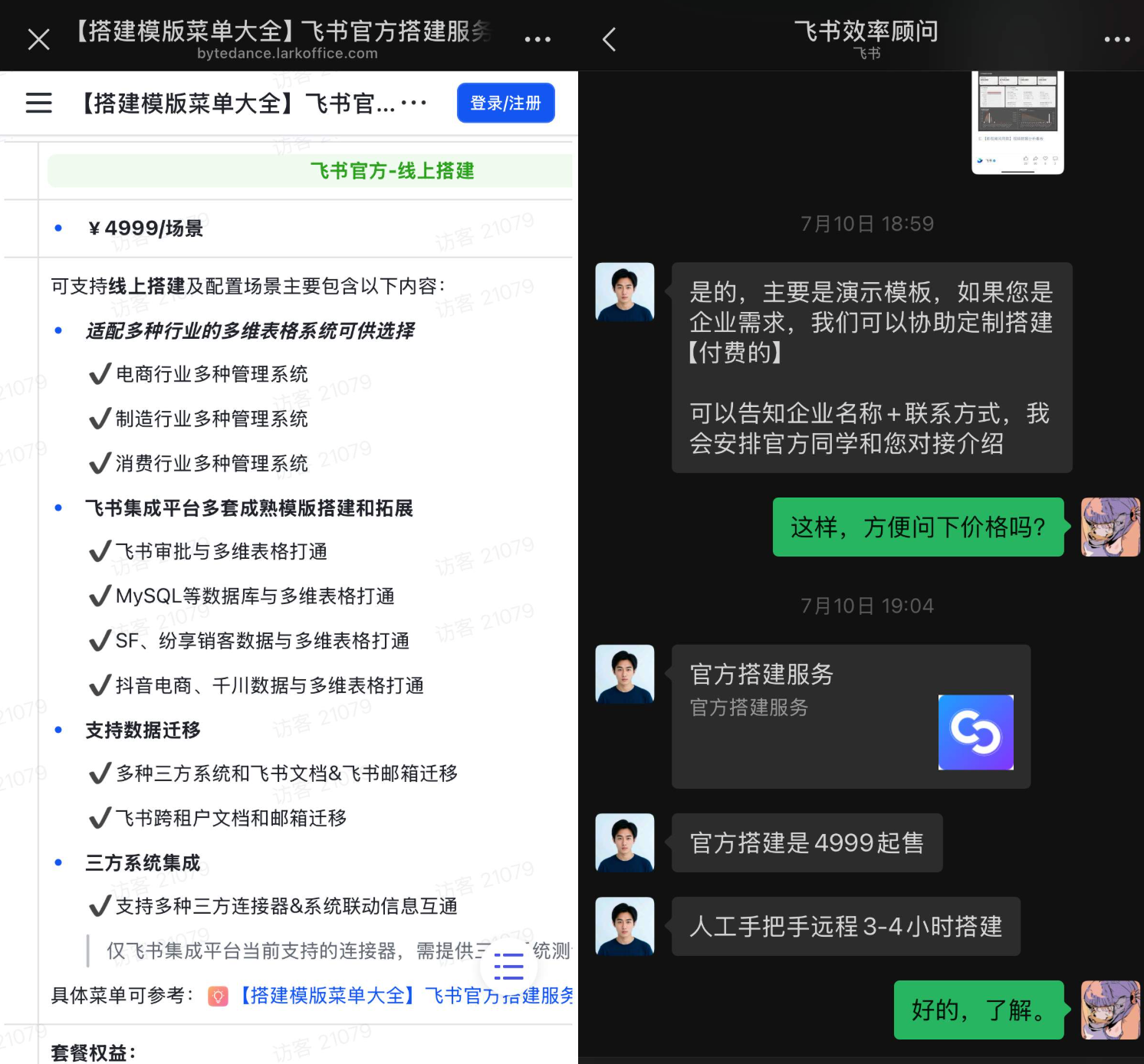
谢谢谢谢,本人读者甚至都没有 4999 人。
买是买不起的,但不当社畜了我可有时间了呀,于是复刻影视飓风同款数据面板的项目就提上了日程。花了三四天用 Trae 实现了基本需求——自动定时获取全平台的粉丝数据、小红书的笔记详情数据,同步飞书多维表格可视化展示,支持本地备份并且同步上传 github。
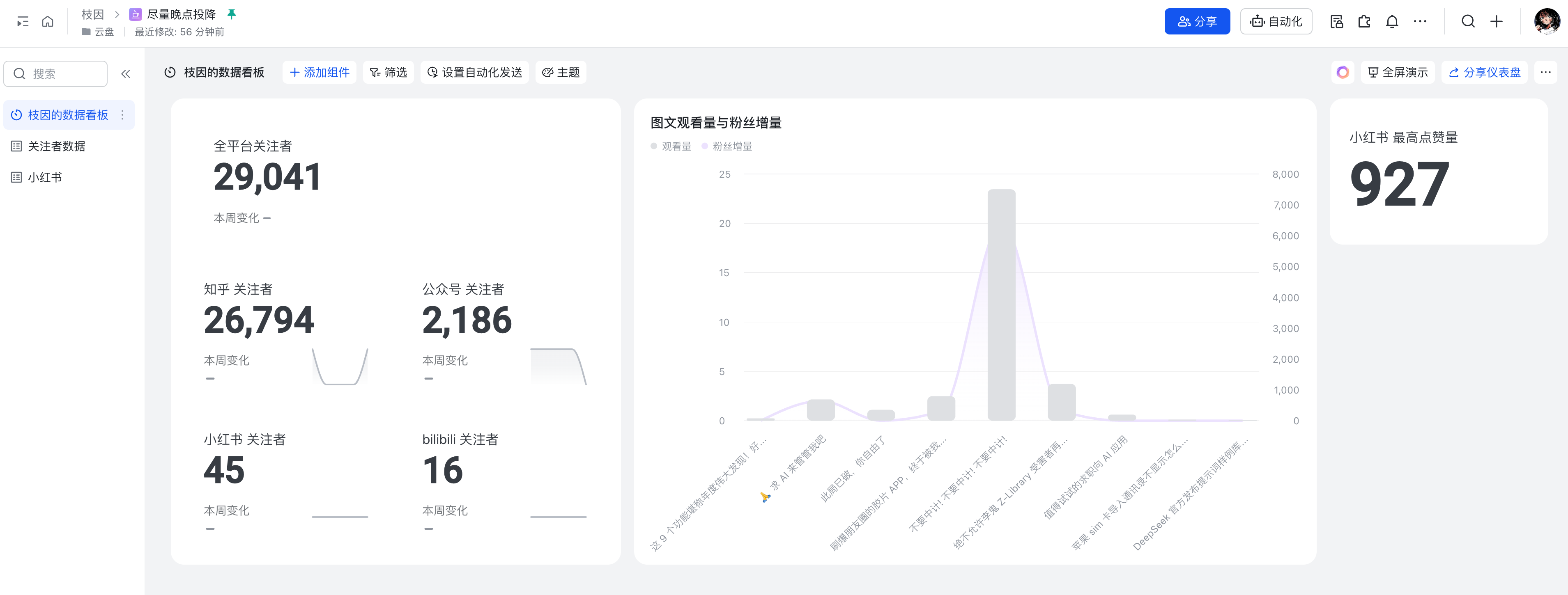
默认是定时早上 9 点运行一次,也可以 @ 机器人+对应关键词来触发实时的数据更新。这俩功能需要脚本长期保持运行状态,最好是有空闲机子当作服务器会方便一些。
说实话很简陋,尤其是用不了官方的 API(因为只面向企业开放) 只好依赖本地 cookie 容易过期失效(尤其是微信公众号),但作为只为麻瓜个人的工具还是够用的——大概这就是 vibe coding 的意义,就算是麻瓜也能手搓一个 for me 的专属工具提效。
这里主要是写个比较详细的配置说明,让如山清抄作业(是的就是写给你的)。
主要的脚本都放在 GitHub上了,先把这个项目下载到本地,确认本地的 Python 环境和相关的依赖(REDME 中有)。然后我们来修改这些脚本,把必要的东西填上。
首先是微博、抖音、bilibili、小红书的 cookie 信息,需要登录后再获取。安装浏览器插件「Cookie-Editor」,进入已登录的 bilibili 页面。第一次使用插件,需要给相关的权限。
再次点击浏览器插件图标,获取 cookie 信息为 JSON 格式,粘贴到对应文件 bilibili_cookie.json 里。
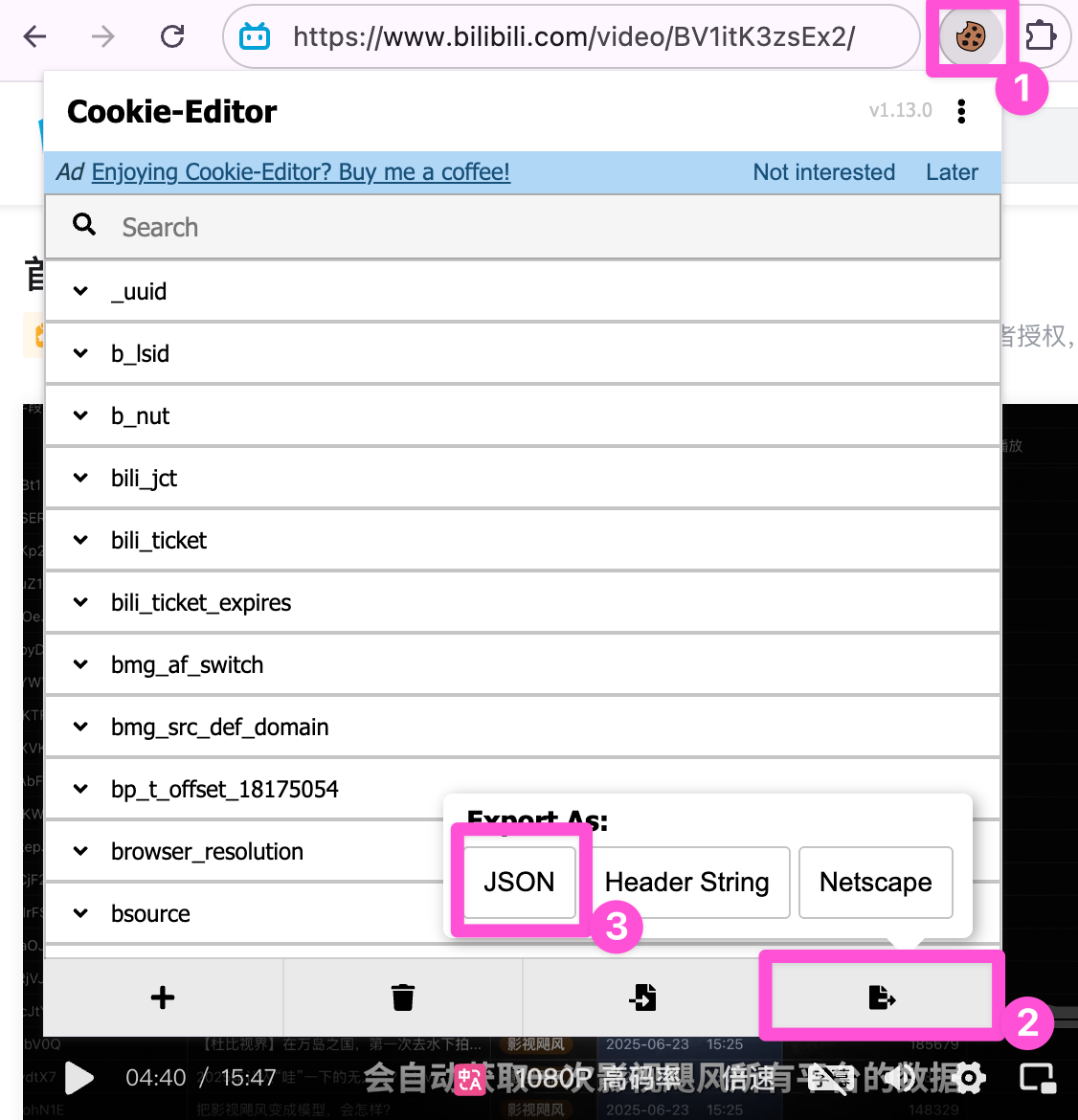
如法炮制,填入对应的 cookie 信息到 douyin_cookie.json、redbook_cookie.json、weibo_cookie.json 里。其实除了小红书之外,其他的不需要那么多 cookie 信息,可以直接在浏览器的开发者工具中通过请求头查看,但用插件点击复制、再粘贴会对麻瓜友好点(反正在本地没太大风险)。
接着我们获取飞书相关的权限,在这个脚本里涉及写入飞书多维表格,这个是通过飞书的自建应用实现的,个人版本的飞书也支持。进入「飞书开放平台」,点击「创建企业自建应用」,填入「应用名称」、「应用描述」和「应用图标」。
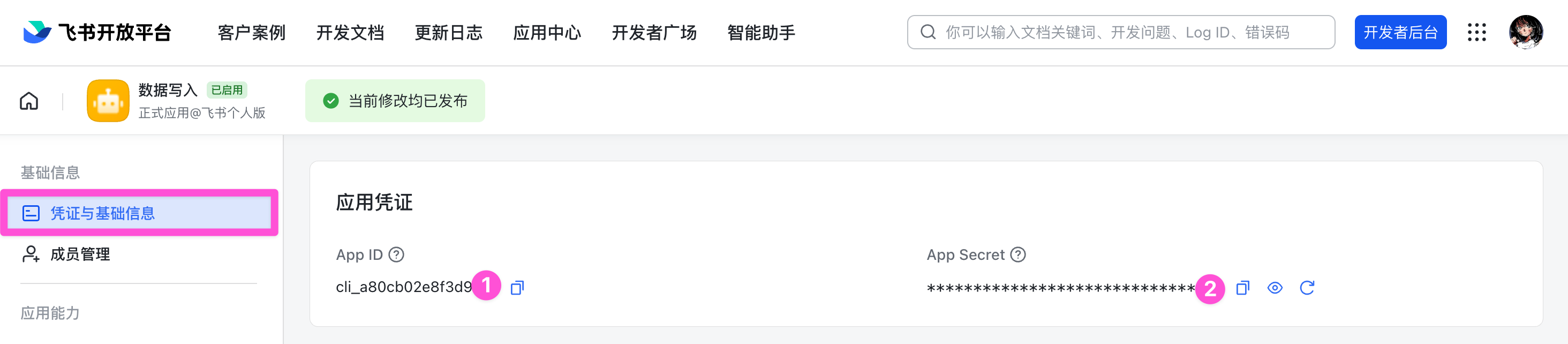
创建成功之后,进入到应用详情,点击「凭证与基础信息」可以找到 App ID 和 App Secret。
进入「权限配置」页面,开启下图中的应用权限。
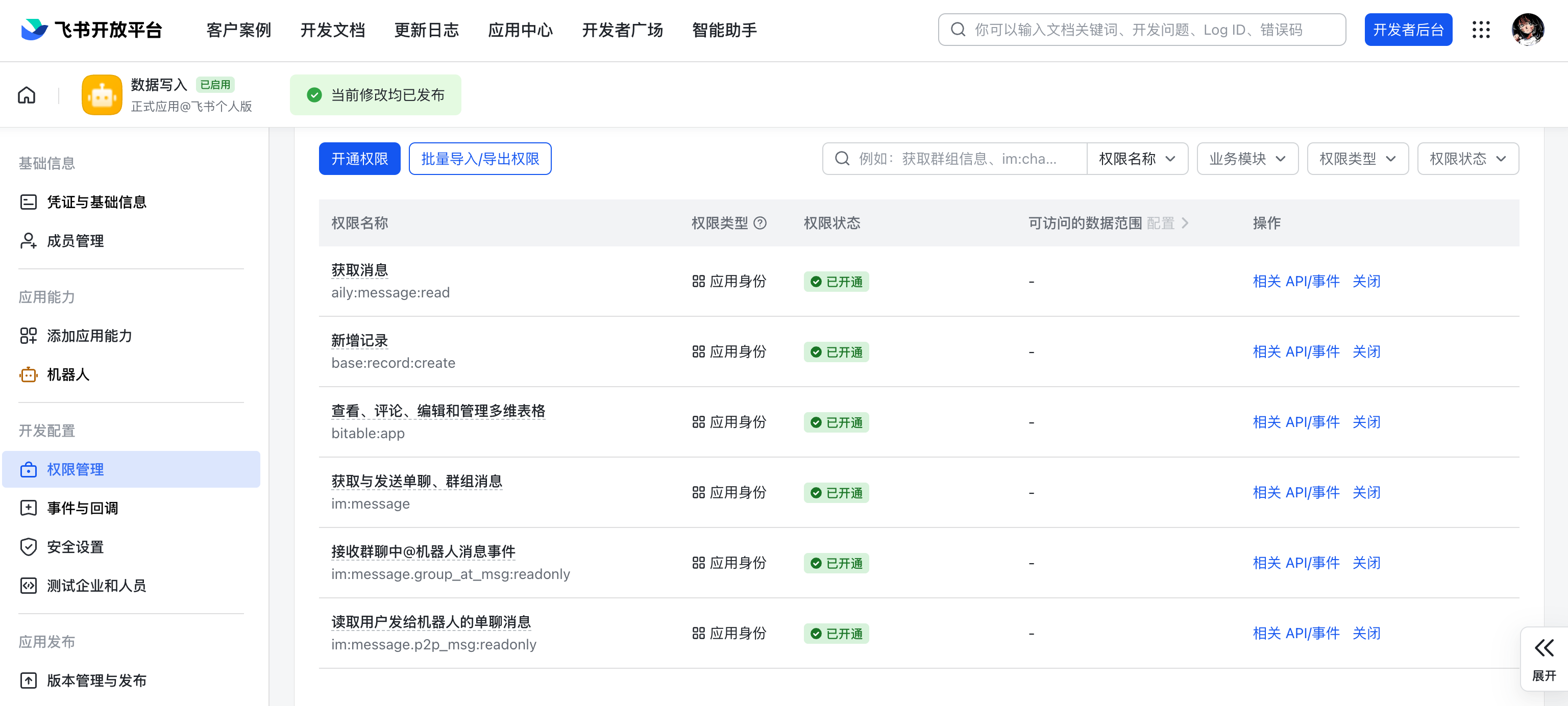
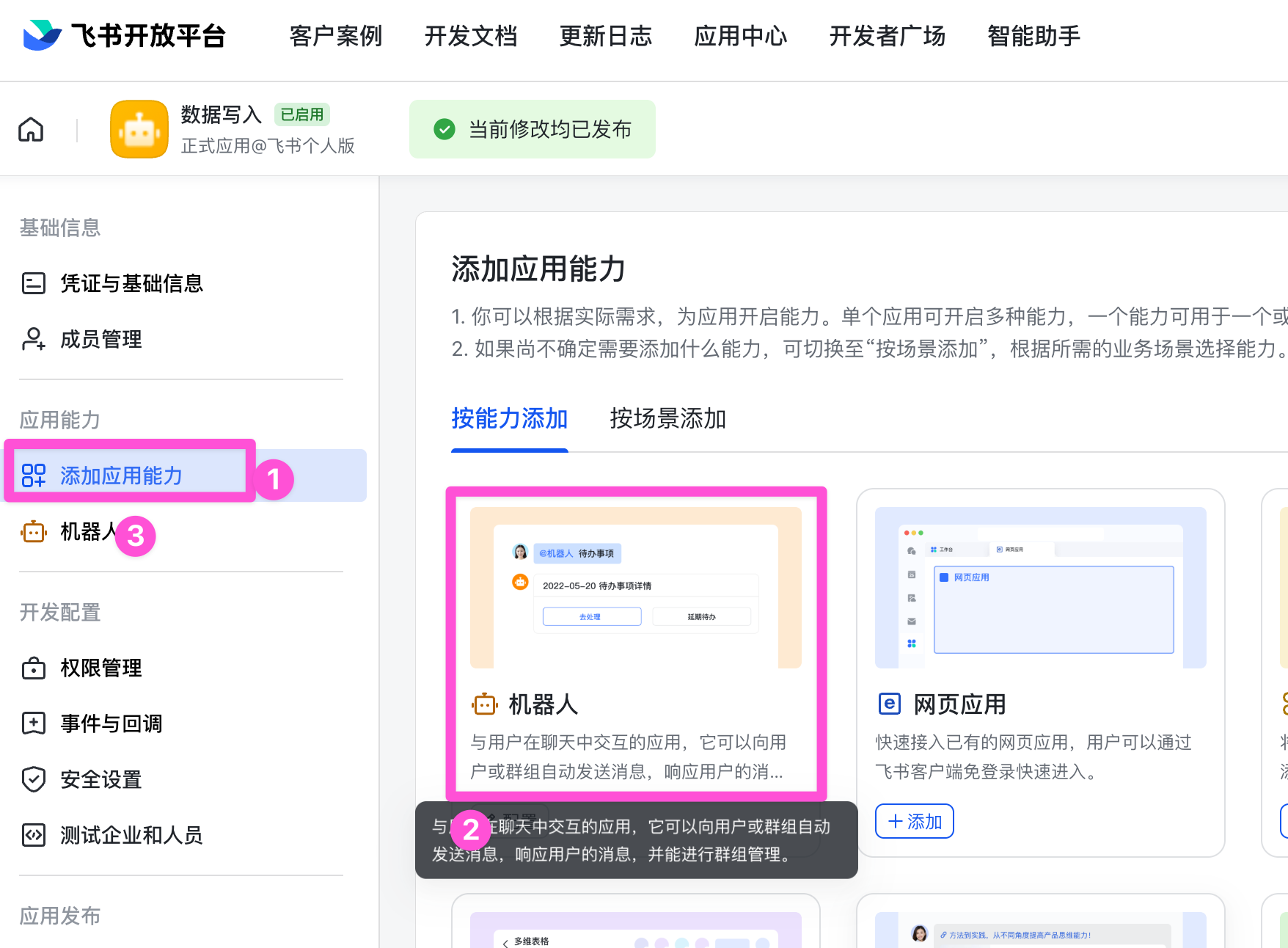
点击「添加应用能力」,选中「机器人」,添加即可。
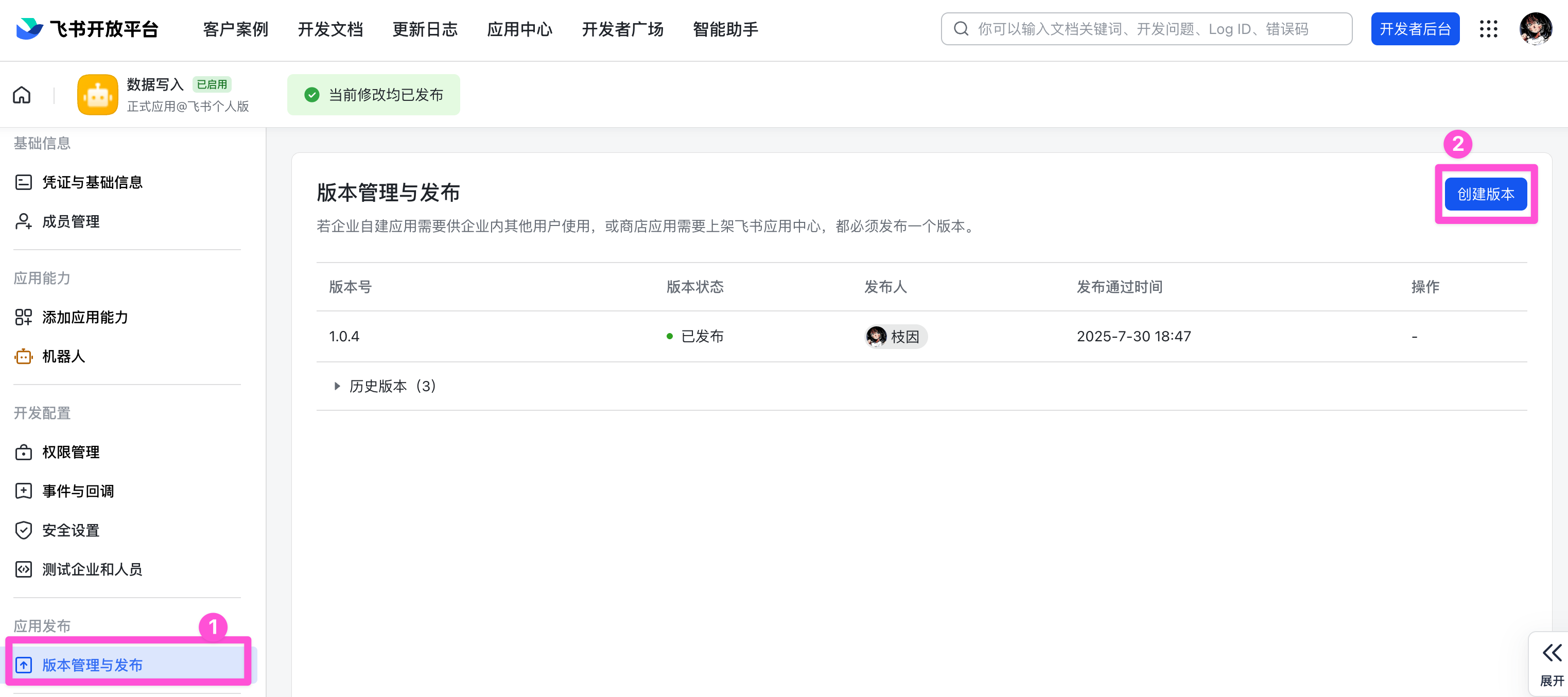
点击「版本管理与发布」-「创建版本」,填入对应信息,发布版本即可。
接着,把面板模板复制一份到自己的飞书。
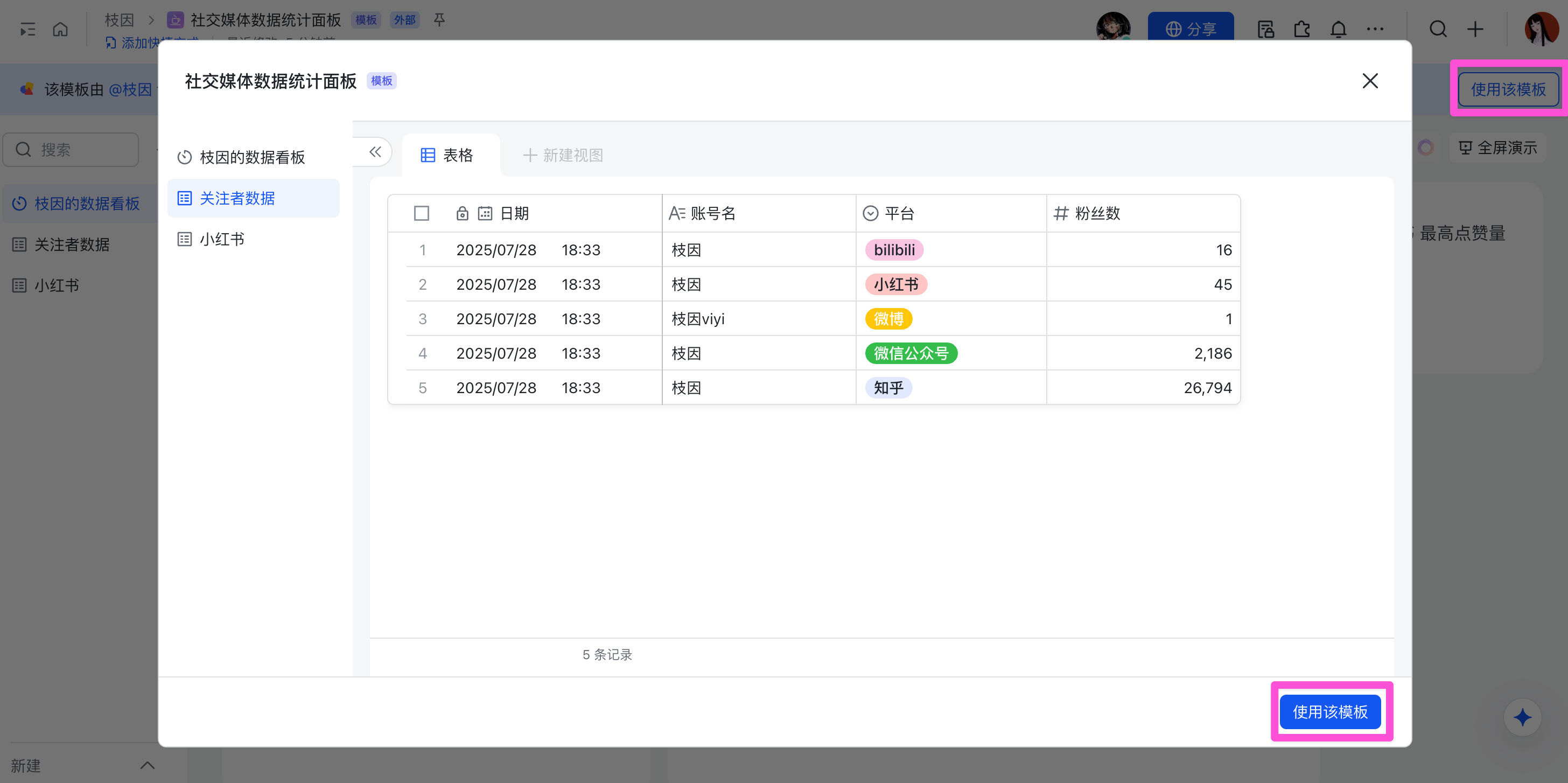
注意,模板存储的位置最好是云盘,而不是知识库,这个会影响多维表格 App 的唯一标识 App Token 的获取方式:
- 如果多维表格的 URL 以 feishu.cn/base 开头:app_token 可直接从 URL 中获取(具体为 URL 中
base/后的部分) - 如果多维表格的 URL 以 feishu.cn/wiki 开头:需调用知识库相关获取知识空间节点信息接口获取,当 obj_type 的值为 bitable 时,obj_token 字段的值即为多维表格的 app_token
下图示例中 feishu.cn 的后面为 base,则粉色高亮部分为 App Token,黄色高亮部分为 Table ID。
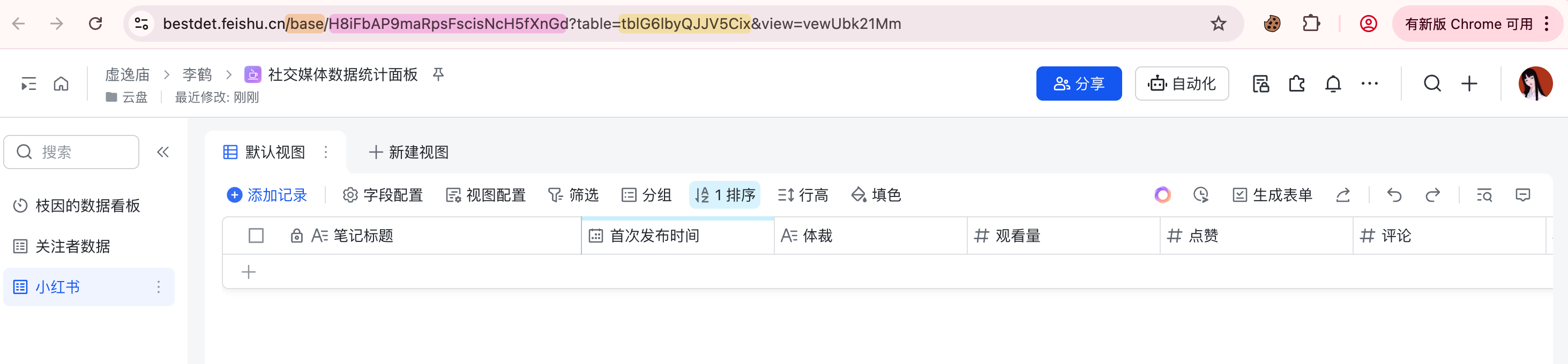
至此,已经获取到 FEISHU_APP_ID、FEISHU_APP_SECRET、FEISHU_APP_TOKEN 和 FEISHU_TABLE_ID,分别填入 redbook.py 和 followers_feishu.py 中即可。
注意 Table ID 有两个:一个是多维表格中「关注者数据」子表的 Table ID 填入 followers_feishu.py,而「小红书」子表的 Table ID 填入 redbook.py。切换多维表格的子表页面,URL 也会同步变化,对应复制即可。
接着将前文创建的应用添加到多维表格中,点击右上角菜单,进入「更多」-「添加文档应用」,搜索应用名字,点击添加。
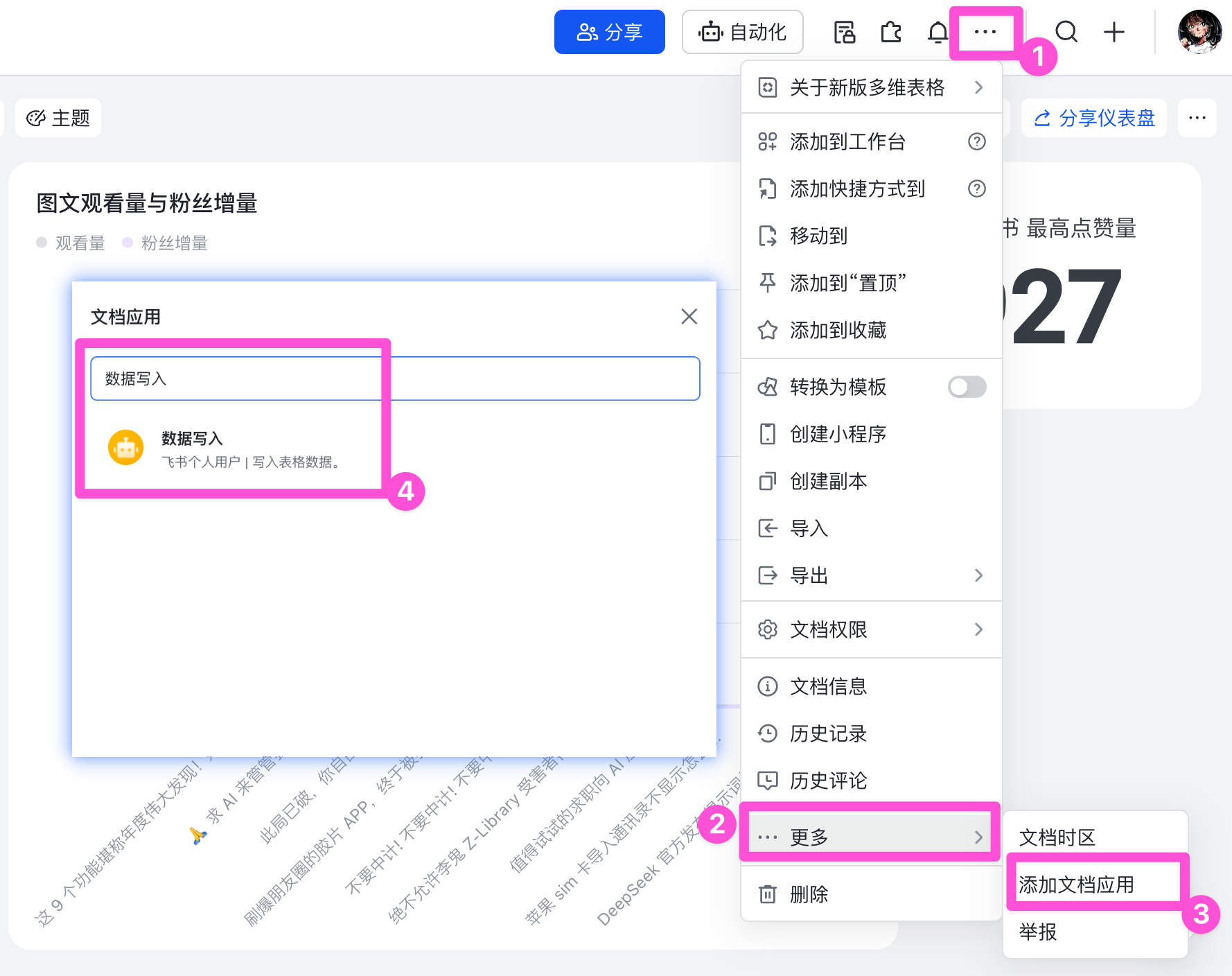
记得把权限设置为「可编辑」或「可管理」,否则会无法写入。
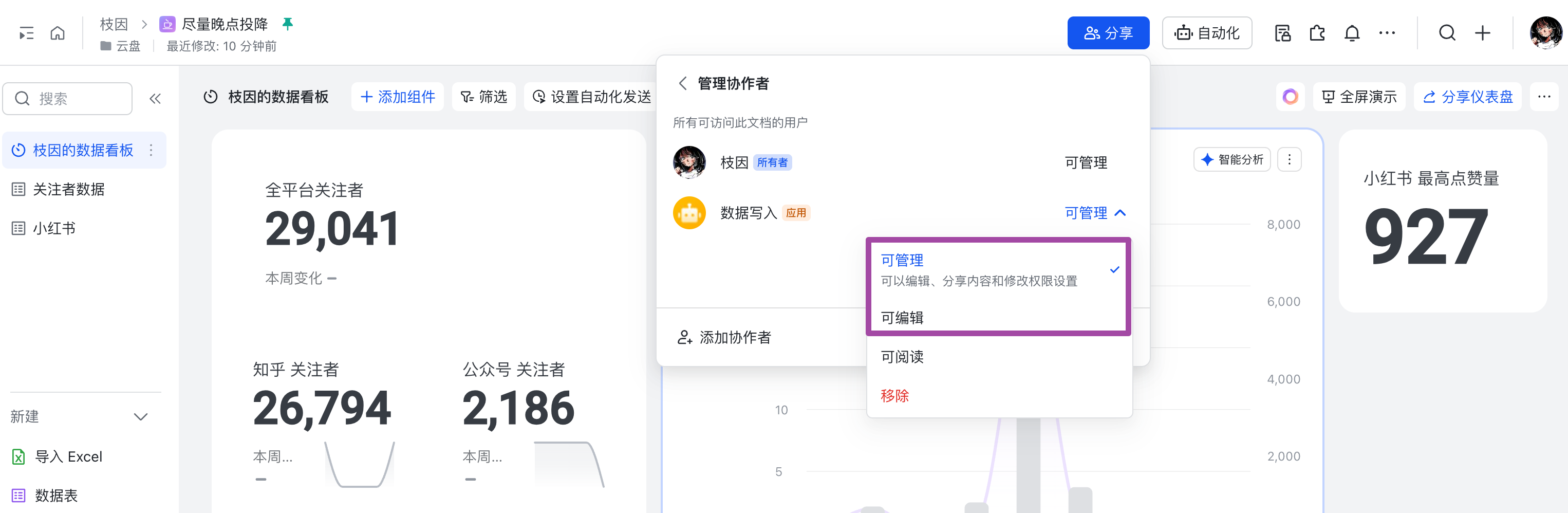
接着,在 followers_feishu.py 中,替换所要监控的平台账号唯一标识符,网页端进入主页即可获取。图示为 bilibili,知乎、微博同样是类似的。

YouTube 的主页链接需要注意填入 about 页(不然获取不到关注者数量),小红书需要的是网页端打开主页中的用户 ID(而不是小红书号)。
微信公众号实际上是通过脚本模拟登录微信公众号助手,然后获取到关注者数据的(因为这个数据并不公开),所以初次使用的时候,会弹出浏览器窗口扫码登录(数据依然是保存在本地的),大概三四天会失效需要重新扫码登录。
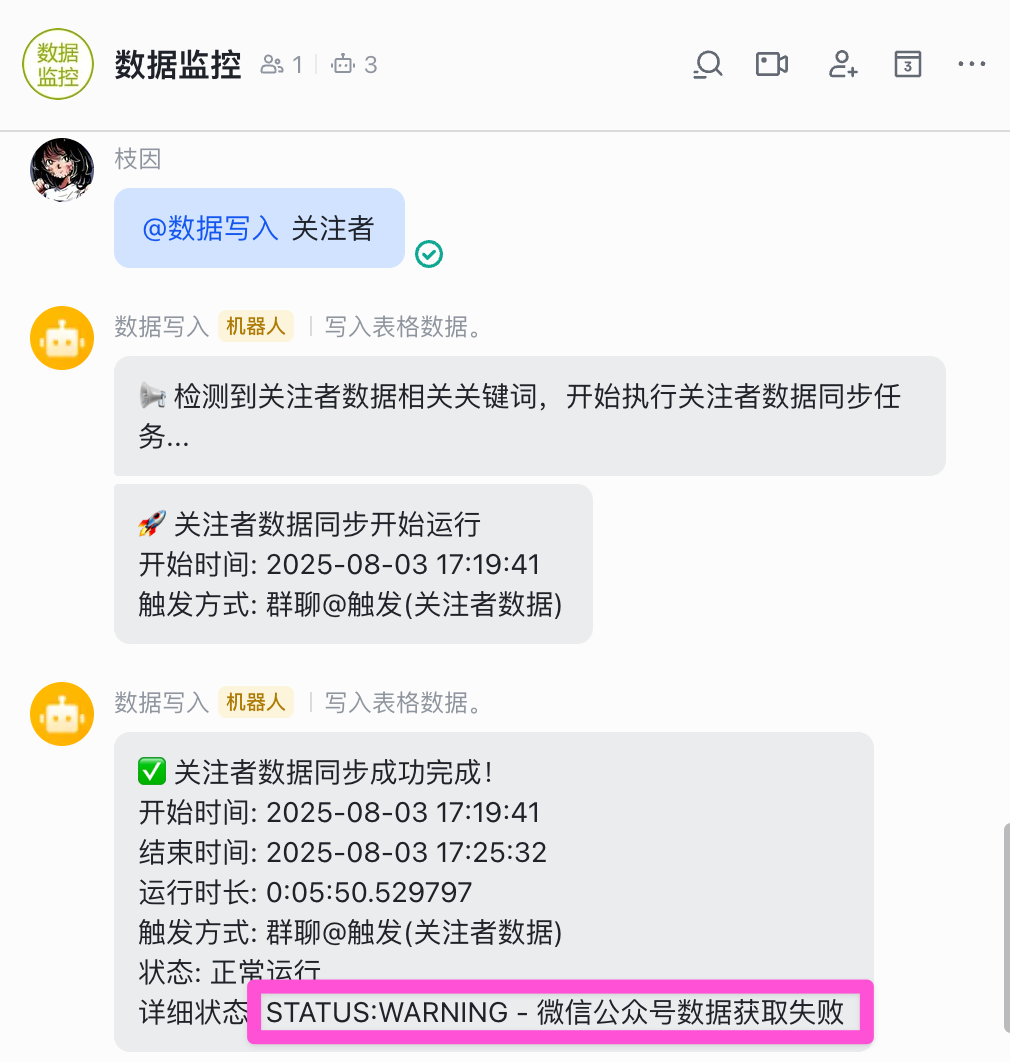
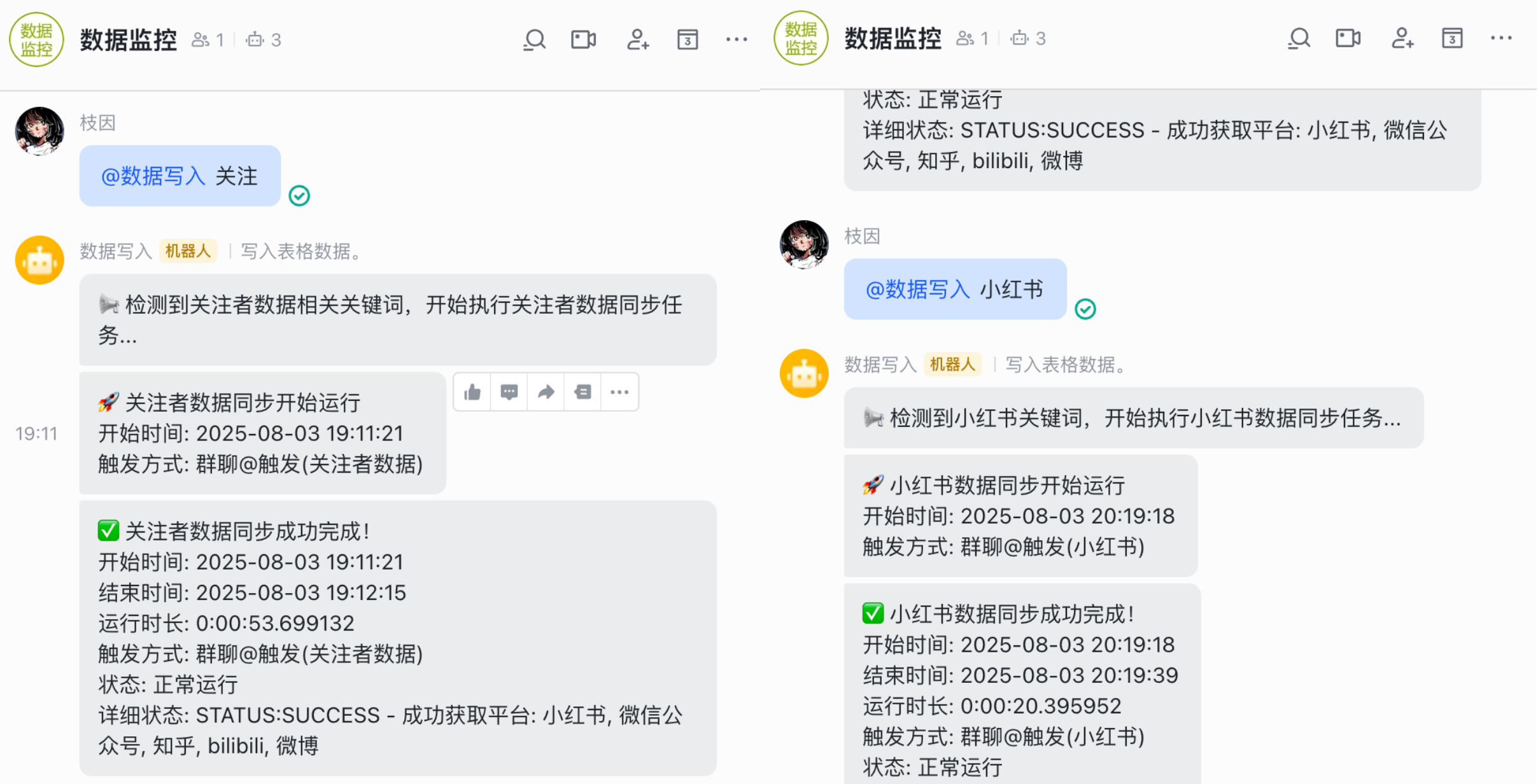
配置完这些,本地运行 redbook.py 和 followers_feishu.py 这两个脚本,就可以实现将多平台的粉丝数和小红书的笔记详情数据同步到飞书多维表格了。如果需要实现上图这种 @ 主动触发,还需要在 monitor_bot.py 中填入 Chat ID 和 Bot Open ID,这个脚本的主要作用就是定时/实时获取数据。
之前帮我看 b 站数据和评论的脚本是通过飞书群聊机器人的 WebHook 实现的,这个数据同步的脚本也就顺手拉进我之前的群聊用了,之前在应用能力里已经开通了机器人服务,因此只需要将应用的机器人添加进群聊即可。
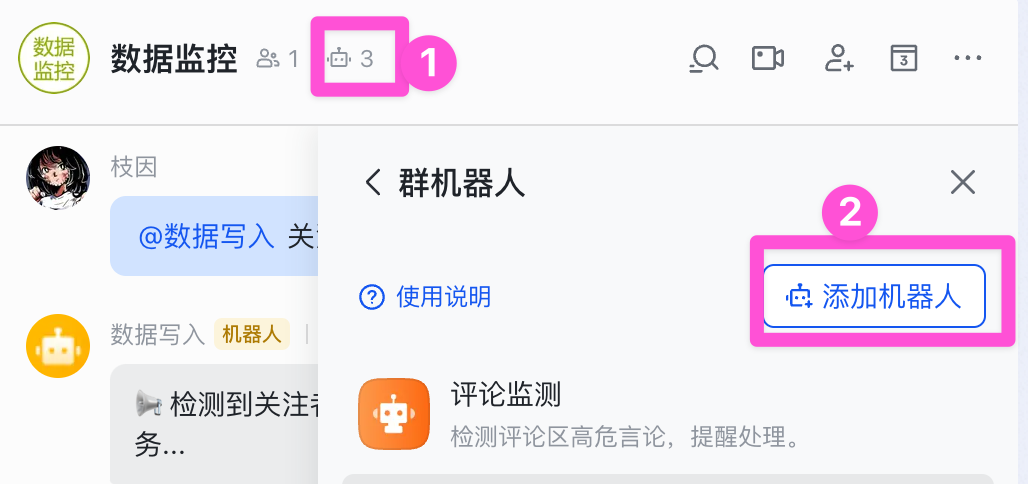
接着我们通过飞书开放平台的 API 调试台来获取 Chat ID,进入「指定群管理员」的页面,点击右侧路径参数下的「获取」按钮,选择对应群聊。
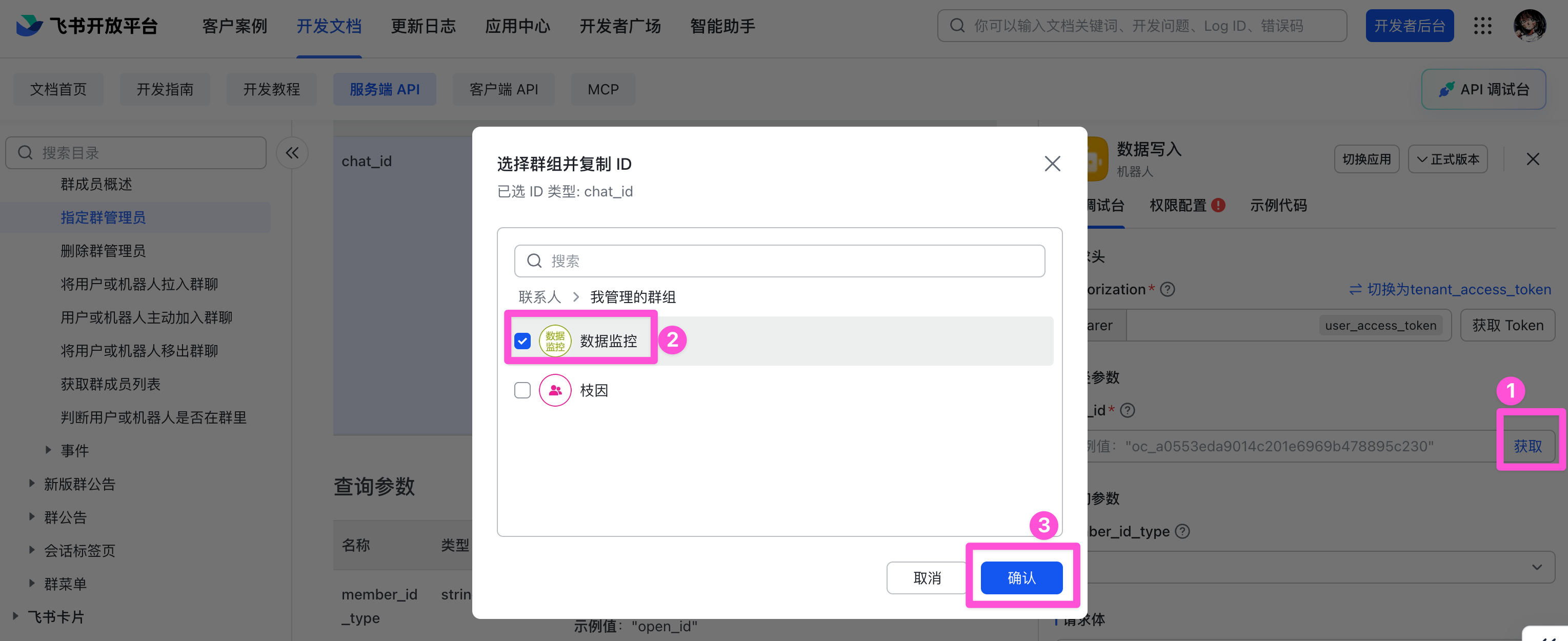
右侧就会获取到 Chat ID,复制即可。

Bot Open ID 稍微麻烦一点,确认应用添加了「机器人」能力之后,参考「获取机器人信息」文档,调用这个接口,在响应体的 bot 对象中可以获取 open_id 字段值。
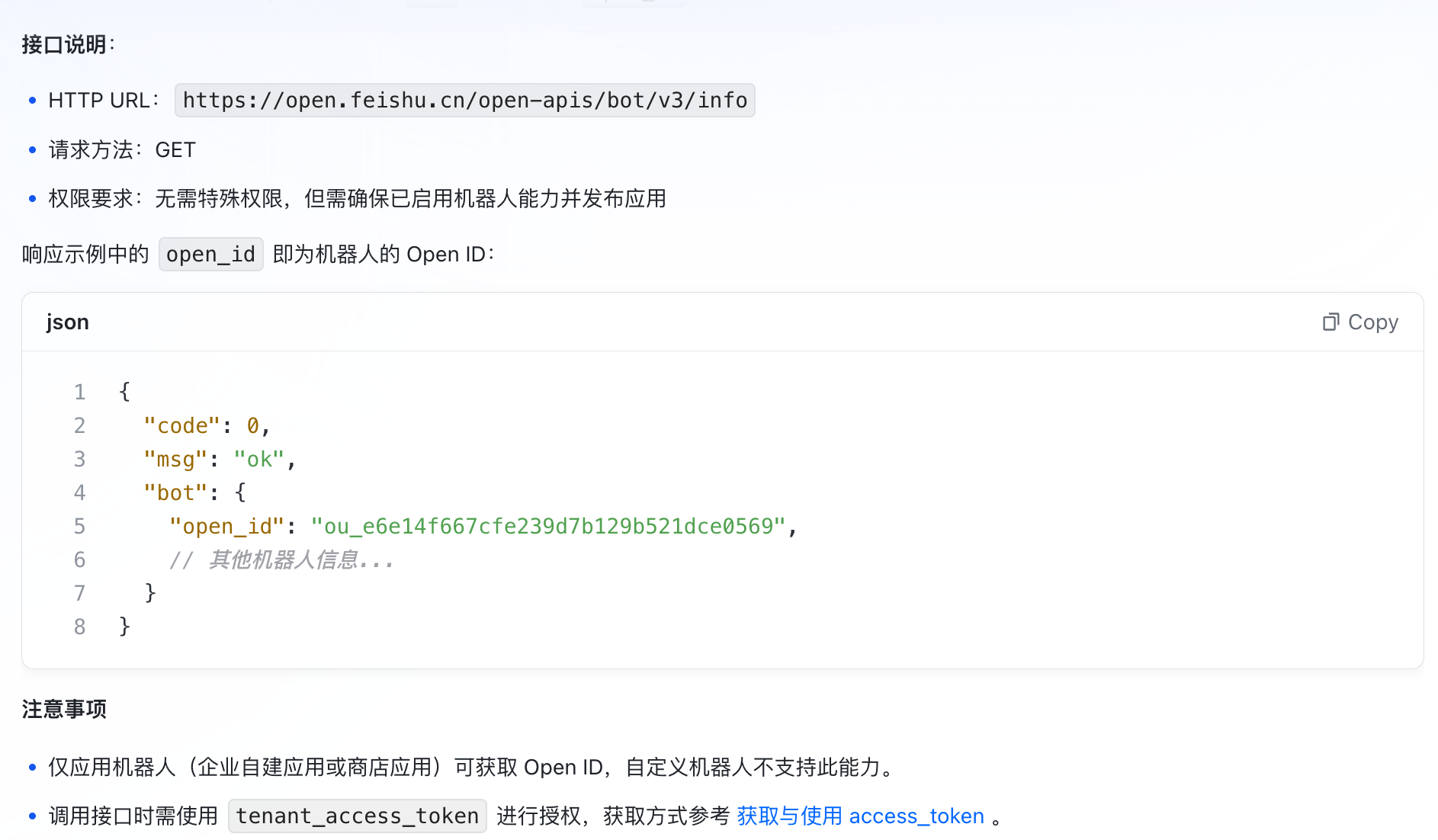
实在是忘记我怎么获取到它的了,应该是把文档链接丢进去然后 Trae 自动处理的。另外,实现完整的 @ 机器人实时更新数据,还需要在飞书应用中配置事件。
需要先运行 monitor_bot.py 这个脚本,它提供了 5 种运行模式:
- 运行一次
- 每日定时监控 (每天早上9点运行)
- 自定义监控间隔
- 启动长连接监听 (支持@机器人触发)
- 启动完整服务 (每日定时监控 + 长连接监听)
先启用第 4 种模式,实现用官方 SDK启动长连接。建立连接之后,再进入应用管理界面的「事件与回调」,添加「接收消息」的事件。
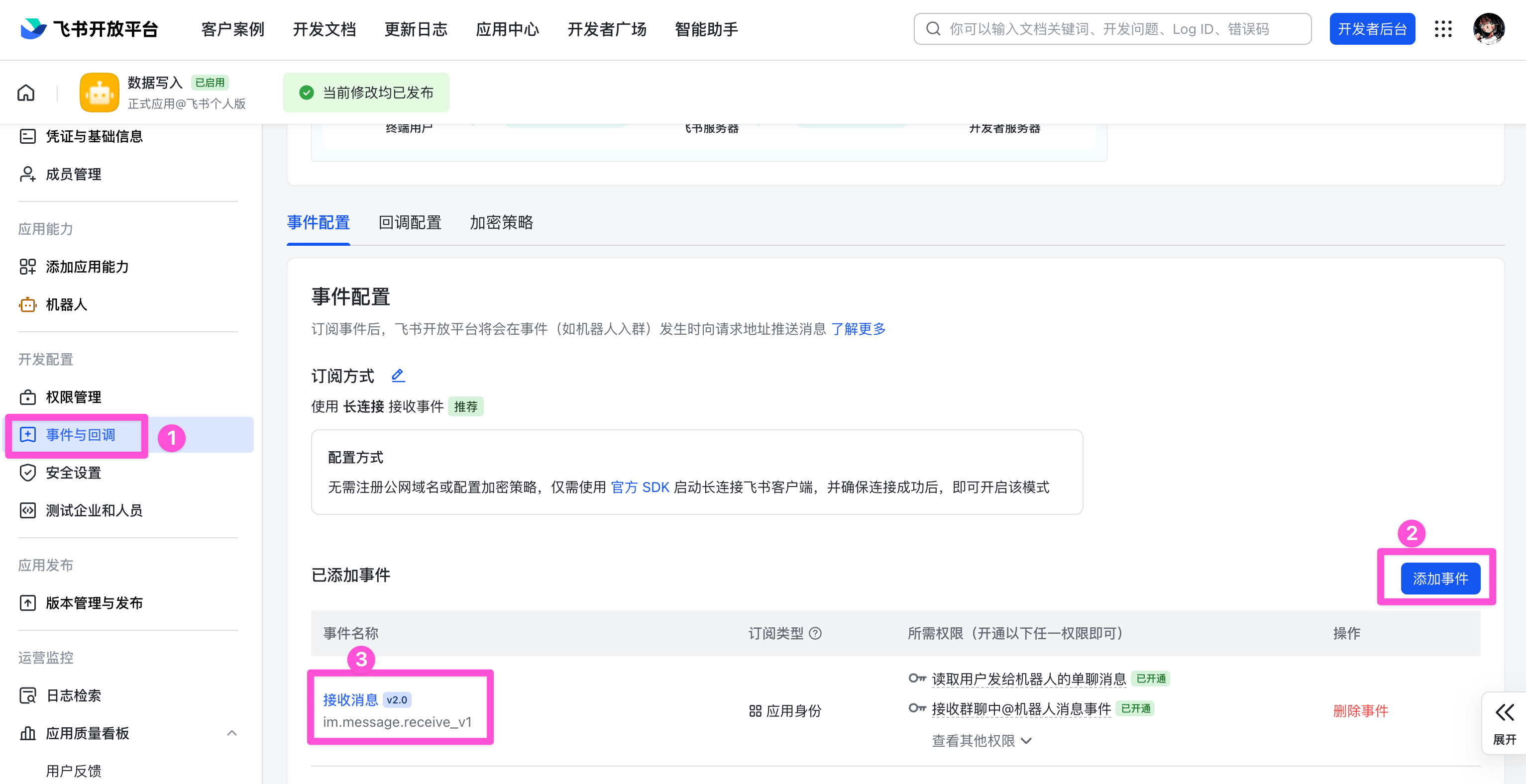
至此,完成所有配置。本地的备份数据会存储在当前路径下的 data 文件夹中,分别为 followers.csv 和 redbook_data.csv。前者是带时间戳的各平台数据,后者则是增量更新。往期某个时间点的小红书数据可以在 downloads 文件夹中查看,这里是从小红书创作者中心导出的图文数据(平台限制仅可导出半年内数据)。
github 的同步会在 monitor_bot.py 执行之后默认进行,需要本地先关联到 github 的仓库。
有空接着完善下去的话,会再添加发布新笔记后定时间隔获取单篇数据的功能,以及公众号的详情数据同步。先挖坑,够用暂时不会再花太多时间修改(。
至于为什么没有影视飓风视频里的 CTR 和 AVD 数据……是因为本质上这俩是仅创作者本人可见的数据,一方面我现在手上没有视频账号,另一方面官方的 API 需要企业身份。个人创作者如果想复刻,可以参考小红书图文详情的获取方式,用脚本操作浏览器从创作者中心导出对应数据,本地清洗备份再写入飞书多维表格进行可视化。