5.3 自然语言处理 (Natural Language Processing)
相较于 2.2 节中讨论过的 “编程语言” 这种词汇量较少、非常结构化的语言类型而言,拥有大量词汇、多义词、口音等特点的人类语言与之完全不同。
代码只能在拼写和语法完全正确时才能编译和运行,而在大多数情况下,人类语言就算有拼写或发音错误,对方也能够理解含义。
我们将人类语言称为「自然语言」(Natural Language),为了使得计算机拥有能够进行语音对话的能力而诞生了「自然语言处理」(Natural Language Processing, NLP),这是结合计算机科学和语言学的跨学科领域。
5.3.1 分析树
词性
单词组成的句子组合方式有无数种,无法通过字典涵盖所有可能。因此 NLP 早期的基本问题是如何为句子分块,其可以通过词性和语法来判断。
以英语为例,英语语音存在 9 种词性——名词,代词,冠词,动词,形容词,副词,介词,连词和感叹词,单类词性下还存在子类,如单数名词 vs 复数名词、副词最高级 vs 副词比较级等。

短语结构规则
但仅依靠词性字典无法处理多重词性的单词在某个语境下的模糊性,需要利用语法辅助判断,故出现「短语结构规则」(phrase structure rules) 来代表语法规则。
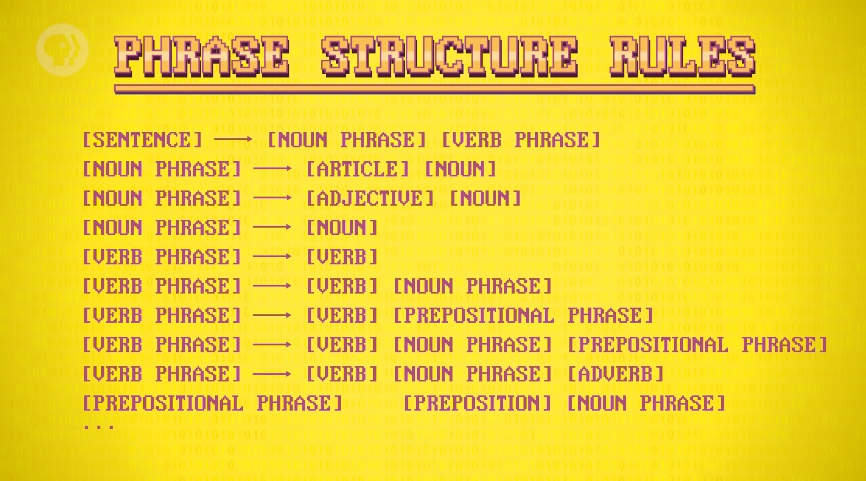
比如英语中有一条规则是 “句子可以由一个名词短语和一个动词短语组成,名词短语可以是 ‘冠词 + n.’ 或 ‘adj. + n.’ 等”,我们可以给一门语言制定出一堆规则,如上图所示。
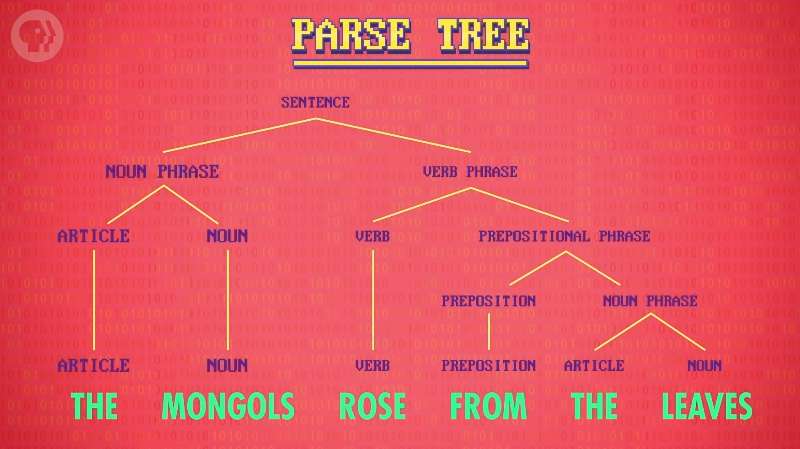
分析树
利用这些 “短语结构规则” 可以做出「分析树」(parse tree),树中注明句子结构和单词词性,使得句子中的数据块更小更易处理。
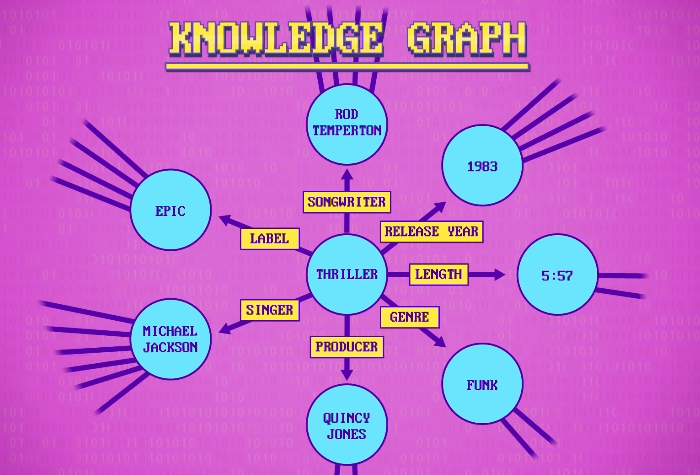
知识图谱
“短语结构规则"和其他把语言结构化的方法,还可以用来生成句子。当数据存在语义信息网络时,这种方法特别有效。实体互相连在一起,提供构造句子的所有成分。
Google 版用结构化方法生成句子的方式称为「知识图谱 」(Knowledge Graph) 。在 2016 年底,包含大概七百亿个事实,以及不同实体间的关系。
5.3.2 聊天机器人
处理, 分析, 生成文字是聊天程序的最基本部件,早期的聊天程序大多是基于规则 (rule-based),后期则使用机器学习进行对话。
基于规则的聊天程序中,会有专家将用户可能会说的话和机器人应该回复的话写成上百个规则,这使得其无法处理复杂对话且难以维护。
一个著名早期例子是 1960 年代中期诞生于麻省理工学院的治疗师聊天机器人 Eliza,它用基本句法规则 (basic syntactic rules) 来理解用户打的文字,然后向用户提问。
如今的聊天机器人和对话系统多使用机器学习完成,通过上 GB 的真人聊天数据来训练聊天机器人用于客服回答,人们也让聊天机器人互相聊天。
在 Facebook 的一个实验里聊天机器人甚至发展出自己的语言,这件事被报道得很吓人,但实际上只是计算机为了提高效率在制定简单协议来帮助沟通。
5.3.3 语音识别 (speech recognition)
发展简史

识别原理
基本过程:将波形转为频谱,识别音素,转成文字。
具体示例如下:
通过麦克风内部隔膜震动的频率,捕捉信号形成声音的 “波形” (waveforms)。
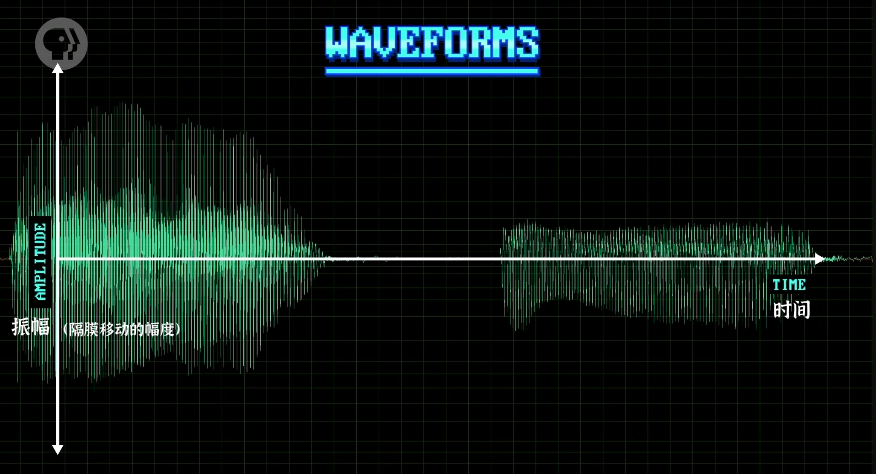
将波形用「快速傅里叶变换」(Fast Fourier Transform, FFT) 转换为 “频谱”(spectrogram)。颜色越亮处,该频率的声音越大,类似于立体声系统的 EQ 可视化器。
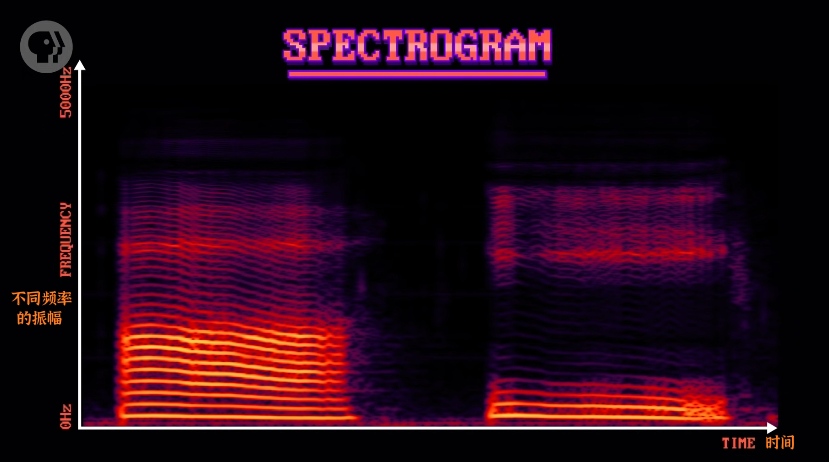
因为发音时人类的声带会放大或减少不同的共振,所以频谱中的信号也会呈现出螺纹状,形成或亮或暗的区域。如果从底向上看,可以标出高峰,称这些峰值为「共振锋」(formants)。
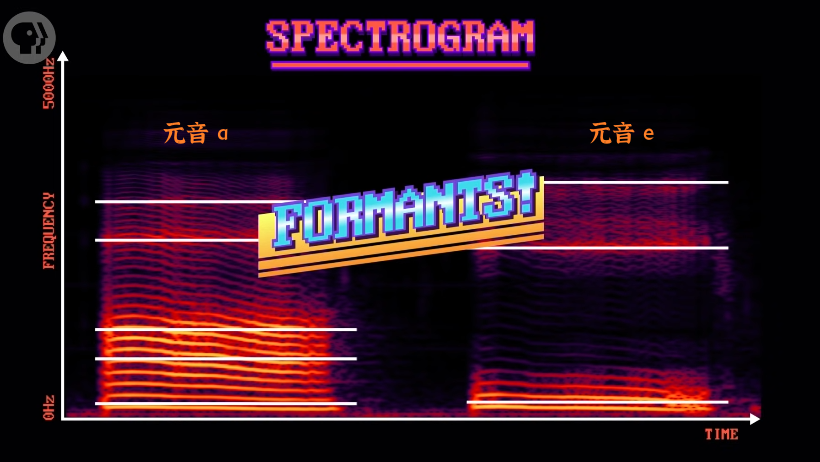
通过对频谱中的 “元音及其共振峰频率组合” 标注值,电脑可以识别出元音,进而识别出整个单词。

构成单词的声音片段,称为「音素」(phonemes)。英语有大概 44 种音素,所以语音识别的本质成了 “音素识别”。

再结合分词、句子始终点确认等方法技术,就可以将语音转成文字。
语言模型
因为口音和发音错误等原因,人们的单词发音有所不同,可以利用语言模型来提高识别准确度。
语言模型中会有单词顺序的统计信息,比如 n. + v. 后大概率是 + adj. 。当识别时不确定 she was 后面紧跟的词是 happy 还是 harpy,语言模型会选可能性更高的 happy。
5.3.5 语音合成
早期语音合成技术,可以清楚听到音素是拼在一起的,比如 1937 年贝尔实验室的手动操作机器。
到了 1980 年代,技术改进了很多,但音素混合依然不够好,产生明显的机器人声。
如今电脑合成的声音,比如 Siri, Cortana, Alexa 好了很多,尽管它们已经非常接近,但还不够像人。
如果语音识别的效果足够好,人们用语音交互的频率会提高,这又给了谷歌,亚马逊,微软等公司更多数据来训练语音系统、提高准确率,这使得人们更愿意使用语音交互,从而形成正反馈循环。