1.9 高级 CPU 设计(Advanced CPU Designs)
1.9.1 瓶颈演变
计算机的计算量日益骤增,从 1Hz 到 1GHz 的 CPU 时钟速度(1.7.1 节),每秒需要执行约十亿条指令是非常庞大计算量。
为了提升计算速度,早期的计算机试图减少晶体管(1.2/1.3 节)的切换时间,但最终碰到了物理瓶颈。
另一种方法是通过硬件电路实现相关操作来加快处理速度,比如通过直接在 CPU 硬件层面中使用专门的电路设计除法,直接给 ALU 提供除法指令,而非像 1.8.1 节中举例的那样通过软件来实现。
现代处理器中有许多类似于除法的专门电路来处理图形操作、解码压缩视频、加密文档等,主要为加快处理速度、减少时钟周期。像是 MMX、3DNOW、SSE 等还有额外电路来做更多复杂操作,用于游戏和加密等场景。
硬件实现的便利使得人们很难删掉指令,于是其不断增加——从 Intel 4004 的 46 条指令到现代 CPU 的 上千条指令,CPU 的计算速度越来越快。新的瓶颈不再是时钟周期,而是读取写入数据的 I/O 操作。
数据的读写需要 RAM 的配合,作为独立部件的 RAM 与 CPU 通过「总线」(bus)连接。尽管接近光速传输的电信号可以通过几厘米的总线很快到达(甚至不计寻址、取数、配置、输出的时间),但与每秒处理上亿条指令的 CPU 来说仍有速度差距。
1.9.2 缓存
缓存(cache)是内置于 CPU 中的仅有 KB/MB 大小的存储器,其作为中转站/临时空间缓和两者的处理速度差异,避免 CPU 在等待 I/O 操作执行时空等。
因数据通常按顺序处理,故 CPU 从 RAM 取数据时,可一次取一批暂存在缓存中。在 CPU 执行时可以直接取用缓存中的数据,仅耗费 1 个时钟周期。
当 CPU 执行复杂的长运算时,缓存也可充当临时空间用于存储计算中间值。
缓存命中
若 CPU 所需数据已在缓存中,称为「缓存命中」(cache hit),反之数据不在缓存中称为「缓存未命中」(cache miss)。
脏位
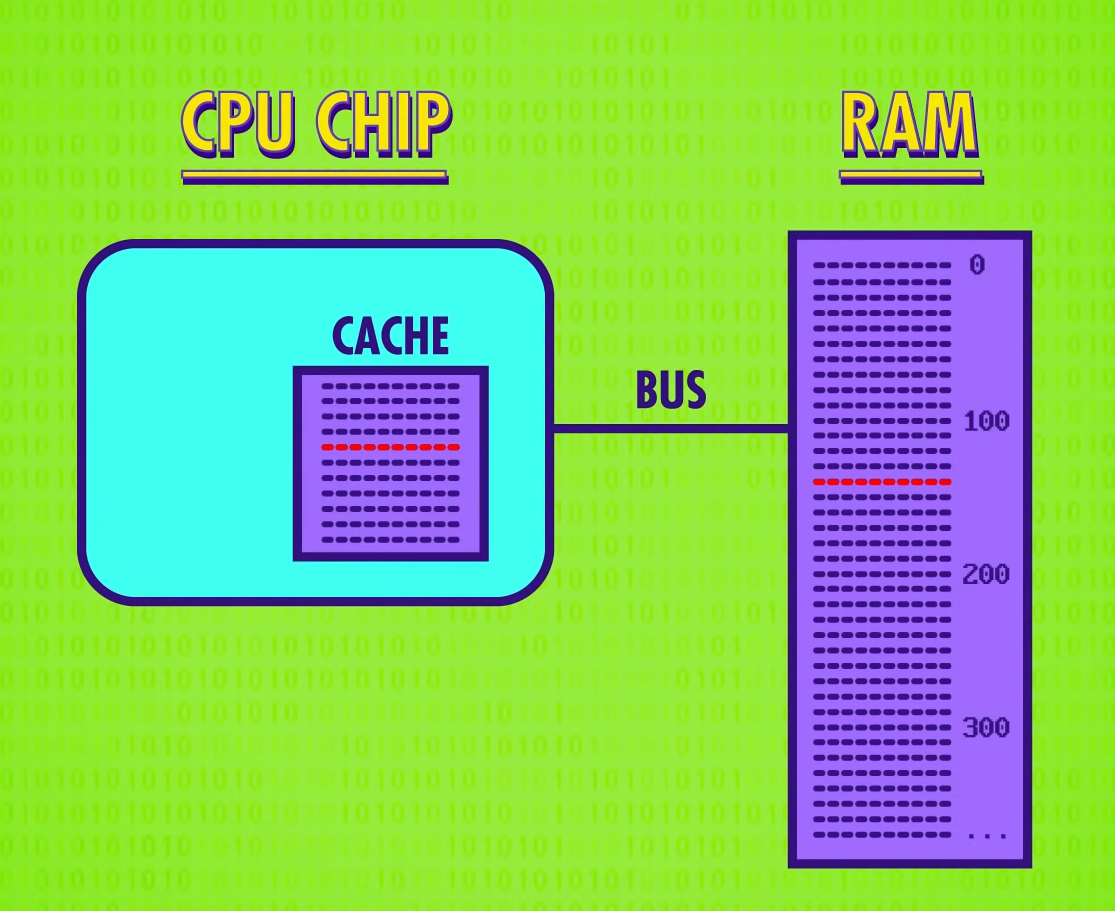
当因计算结果暂存在缓存中等原因,使得缓存中数据与 RAM 中的数据值不一致时,需要通过缓存中的特殊标记位「脏位」(dirty bit)记录,以便之后同步。
同步
同步通常发生在缓存已满,但 CPU 又需要使用缓存时。在清理缓存之前,CPU 会先检查脏位,若该位已“脏”则先将数据写回 RAM 后再加载新内容。
1.9.2 指令流水线
指令流水线(instruction pipelining)是指当指令执行的各个阶段使用的是 CPU 不同部分时,将其并行处理(parallelize)的执行方式,像是做饭等水开的时候先去切菜。
原本的「取指 -> 解码 -> 执行」需要 3 个时钟周期才能完成一个指令,并行后可以在每个时钟周期内处理 1 个指令,使得其吞吐量(throughput)翻三番。
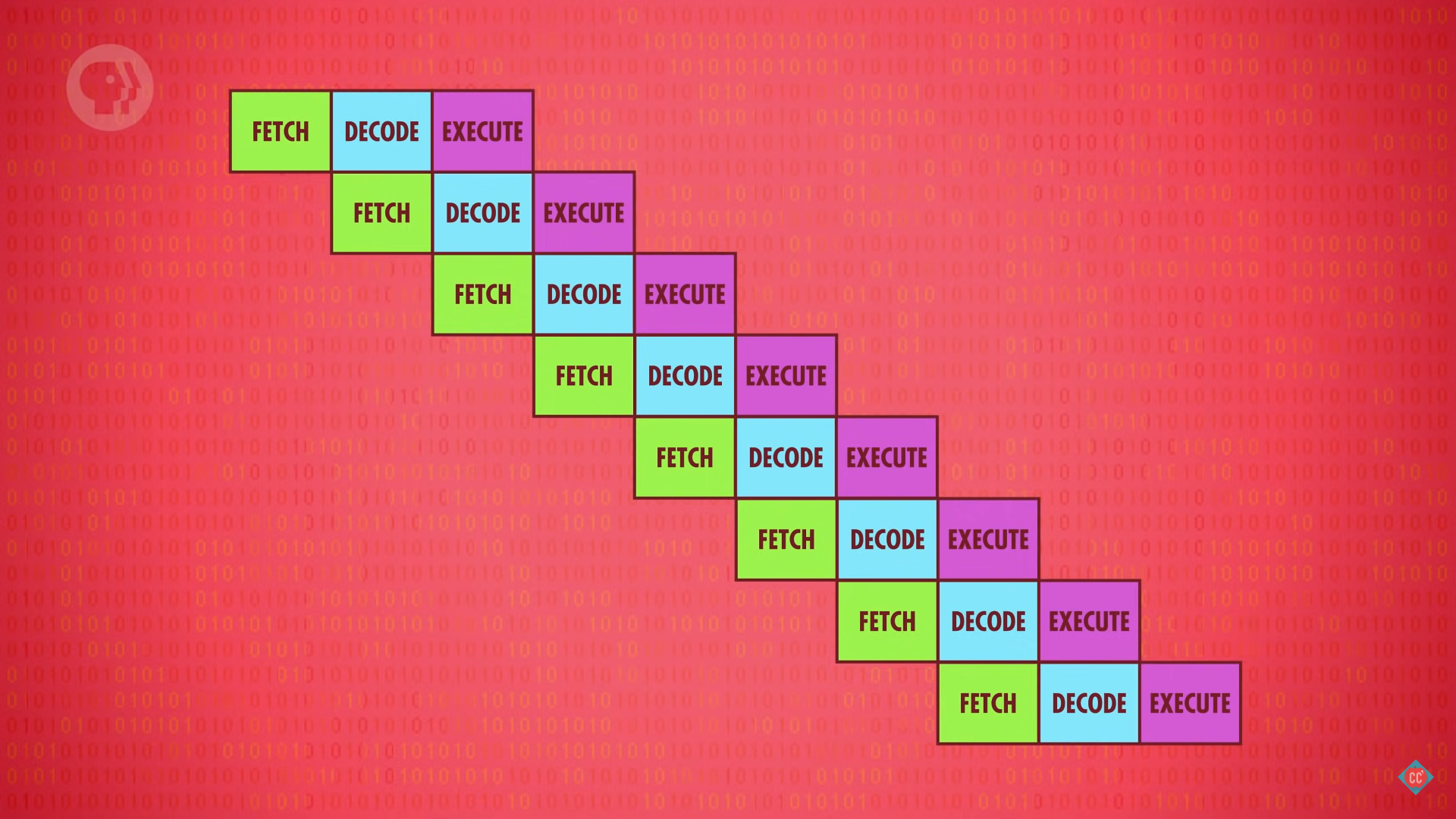
指令流水线加快了处理速度,也带来了新的问题——数据依赖性(a dependency in the instructions)和执行流(exexution flow)的改变。
数据依赖性与乱序执行
指令之间的前后依赖关系称为数据依赖性,比如在读取某个数据时,当前正在执行的指令会修改该数据,我们就会拿到旧数据。流水线处理器(pipelined processors)需要弄清楚这种数据之间的依赖关系,必要时停止流水线操作以避免出错。
在高端的 CPU 中,使用「乱序执行」(out-of-order execution)来最小化流水线的停工时间,这种复杂电路其能够动态性排序有依赖关系的指令。
执行流改变与推测执行
“条件跳转”之类的指令会改变程序的执行流,简单的流水线处理器会等待 JUMP 条件值确定后执行,复杂的流水线处理器为避免出现这种空等延迟会采用「推测执行」(speculative execution)。
推测执行是指高端 CPU 会猜测 JUMP 的结果(在岔路口选择路径),提前将指令放进流水线。猜对则立即运行,猜错就清空流水线。
为了减少猜错清空的次数,CPU 厂商使用更为复杂的方法来预测哪条分支更有可能,称为「分支预测」(branch prediction),现代 CPU 的正确率超过 90%。
超标量处理器
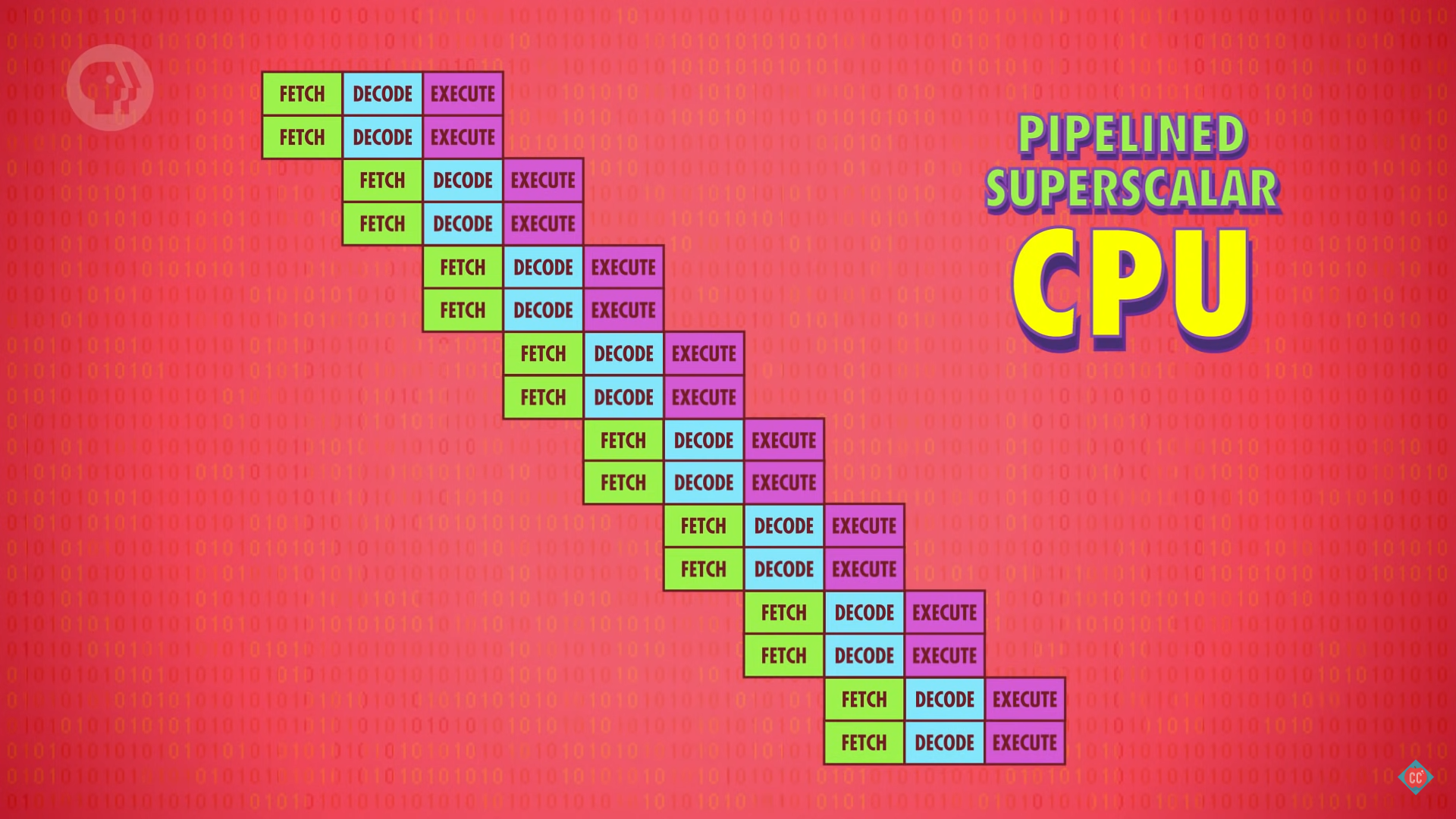
理想情况下,指令流水线在 1 个时钟周期完成 1 个指令,而可以在 1个时钟周期完成多个指令的处理器称为「超标量处理器」(superscalar processors)。
这种处理器会一次性处理多条指令(取指令 + 解码),通过增加几个相同的电路执行高频指令,以便同时处理多条指令。比如很多 CPU 中会有 4/8/more 完全相同的 ALU 支持执行多个数学运算。
1.9.3 多核处理器
除了上一小节中谈及的优化 1 个指令流的吞吐量来提升 CPU 性能之外,还可以使用多核处理器同时运行多个指令流。
多核处理器是指在一个 CPU 芯片中有多个独立处理单元,其共享缓存等资源,可以合作进行运算。如双核处理器(dual-core processors)或是四核处理器(quad-core processors)。
1.9.4 超级计算机
当多核处理器也无法满足运算需求时,可以使用多个多核处理器。最常见的是使用 2 个或是 4 个CPU ,而如果要模拟宇宙形成这种怪兽级别的运算(monster calculations)则需要使用超级计算机(supercomputer)的运算能力。
超级计算机一般拥有着上万个 CPU,每个 CPU 有着上百个核心,每个核心的频率达到 GHz,每秒可以进行亿亿次量级的运算。
截至 2022 年 11 月,世界上最快的计算机是美国橡树岭国家实验室的 Frontier,总共超过 8 千万个核心,每个核心的运算是 2GHz,每秒可运行 110.2 亿亿次浮点运算,这也称为每秒浮点运算次数(FLOPS)。