1.4 二进制表示法(Representing Numbers and Letters with Binary)
“Everything is number.”by Pythagoras
「万物皆数。」——毕达哥斯拉
1.4.1 二进制
在二进制中,每个符号就是二进制元数字(0/1)中的一个二进制位 (binary digit) 或是称之为一位 (bit)。
二进制基数为 2,位权为 2 的整数次幂。用 0 和 1 这两个数字表示,逢二进一。
| $2^0$ | $2^1$ | $2^2$ | $2^3$ | $2^4$ | $2^5$ | $2^6$ | $2^7$ | $2^8$ | $2^9$ | $2^{10}$ | $2^{11}$ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 |
| $2^{12}$ | $2^{13}$ | $2^{14}$ | $2^{15}$ | $2^{16}$ |
|---|---|---|---|---|
| 4096 | 8192 | 16384 | 32768 | 65536 |

计算机中的数据常用 8 位表示,又名 1 字节(1 bit = 1Byte)。8 位二进制可按 3 位为一组(高位补零)转换为八进制:
| 八进制 | 二进制 |
|---|---|
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
1.4.2 进制转换
十进制转二进制则「除基逆序取余」,二进制转十进制则「乘位权后相加」。
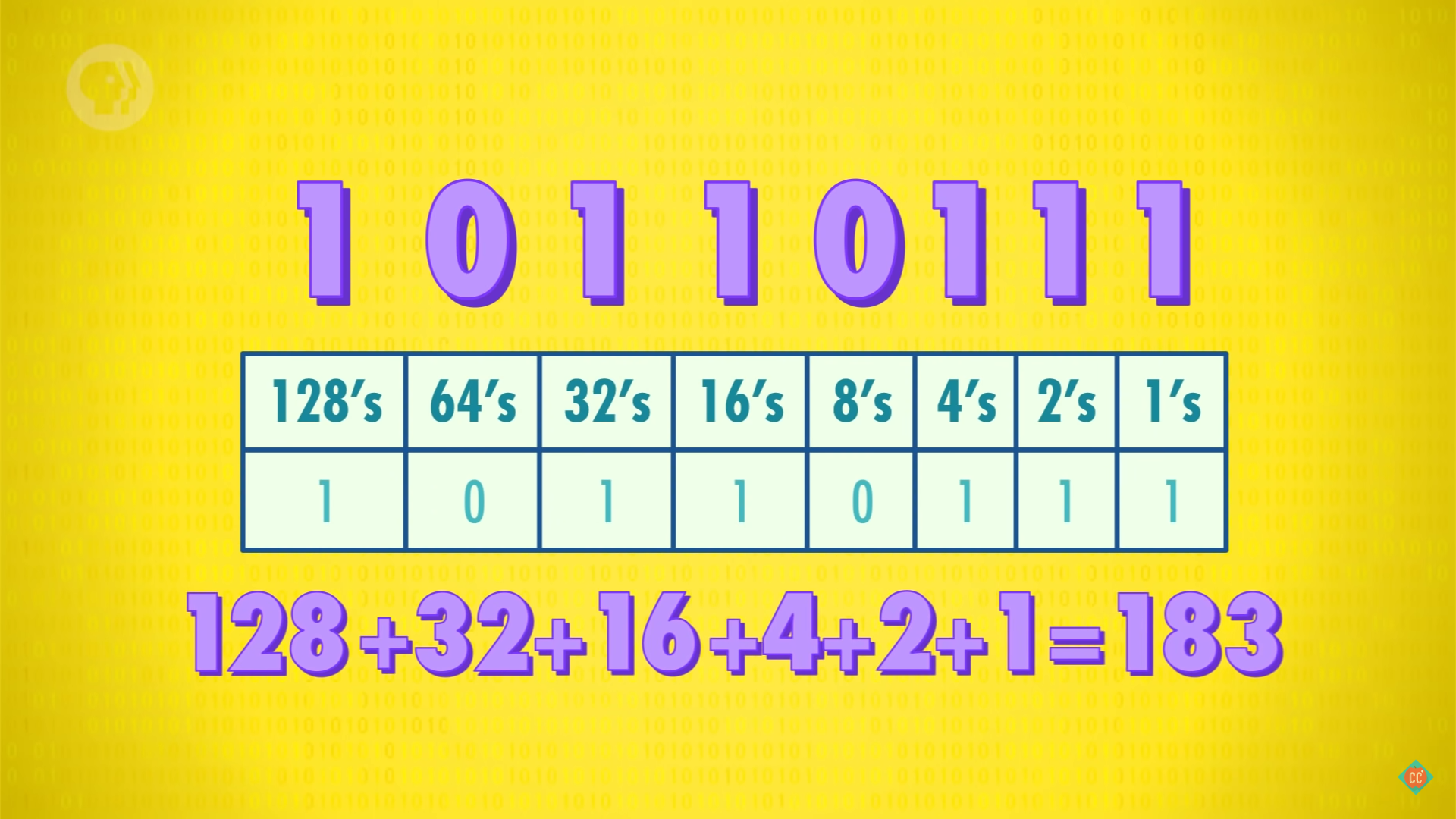
1.4.3 单位换算
因 $10^3=1000$ 与 $2^{10}=1024$ 是近似值,故在某些时候 KB 所描述的两种含义经常混用(i.e. 1KB = 1000 or 1024 Byte 均正确)。
通常来说描述存储容量或是文件大小时以 2 为底,描述频率或速率时以 10 为底。e.g. 32 位或 64 位计算机是指每次按块处理数据的单块长度位 32b 或 64b(32b 可表示的最大数约为 43 亿,64b 则为 $9.2^{10}$)。
| 十进制术语 | 缩写 | 数值 | 二进制术语 | 缩写 | 数值 | 数值差别 |
|---|---|---|---|---|---|---|
| kilobyte | KB | $10^3$ | kibibyte | KiB | $2^{10}$ | 2% |
| megabyte | MB | $10^6$ | mebibyte | MiB | $2^{20}$ | 5% |
| gigabyte | GB | $10^9$ | gibibyte | GiB | $2^{30}$ | 7% |
| terabyte | TB | $10^{12}$ | tebibyte | TiB | $2^{40}$ | 10% |
e.g. 1KB = 1000B = 8000b;1MB = 1000KB etc.
1.4.4 负数与浮点数
为了便于存储数据,计算机将内存中的位置标记称为「位址」(memory addresses)。当硬盘(memory)的容量到达 GB 和 TB 这样上万亿字节的量级时,需要用 32/64 位的数字来表示位址。
地址无需区分数字的正负,在其他情况下则需要区分(银行存款)。此时可用 32 位中的第 1 位标识正负(1 负 0 正),剩下的 31 位表示数字本身(实数),可表示范围为 ±20 亿左右( $-2^{31}$ ~ $2^{31}-1$ )。
非整数因其小数点可以在数字中浮动而称为「浮点数」(Floating Point Numbers),其最常见的表示标准是 IEEE 754 标准。该标准使用类似于科学计数法的方式存储十进制值。
具体表示方法为「浮点数 = 有效位数 × 指数」,以 32 位浮点数为例,第 1 位表示正负,第 2~9 位则表示指数,剩下 23 位存储有效位数。e.g. 625.9 = 0.6259(有效位数)× $10^3$(指数)
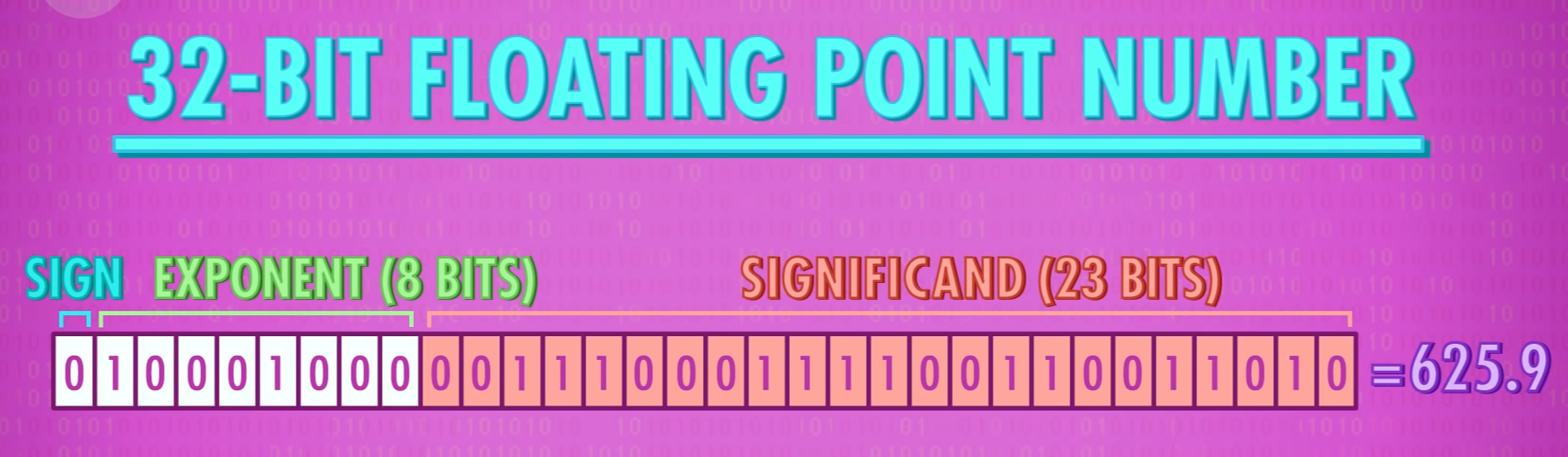
1.4.5 字符
英国作家弗朗西斯·培根(Francis Bacon)曾用 5 位序列来编码 26 个英文字母,在 1600s 传递机密信件。5 位最多可表示 $2^5=32$ 个数字,足够容纳英文字母,但无法表示符号与数字以及大小写字母。

ASCII
ASCII 全称为美国信息交换标准代码(American Standard Code for Information Interchange),于 1963 年发明,使用 7 位代码表示 128 个不同的值。
在 ASCII 中,除了大小写字母、数字以及常用符号之外,还有一些特殊命令符号。比如使用换行符(图中 10)进行换行。
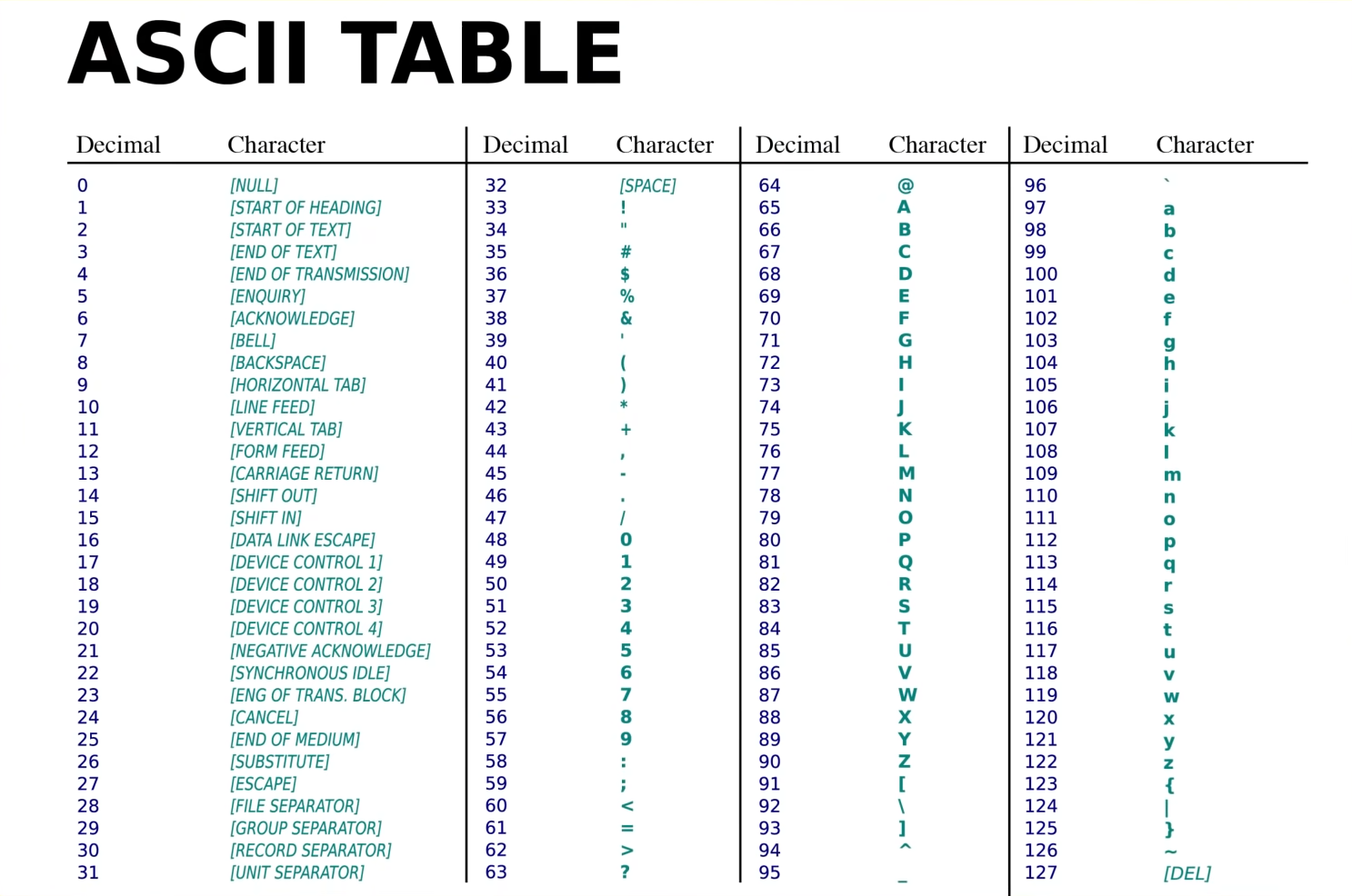
ASCII 的出现使得不同公司所制造的设备之间能够交换数据,我们将这种能够通用交换信息的能力称为「互用性」(interoperability)。
ASCII 为英文设计,在其他非英语国家不够通用。因电脑中 1 字节有 8 位,ASCII 中未使用的 128~256 可供各个国家进行再次编码。常见用途如下:
- 美国:主要用于编码附加符号,如数学符号、图形元素或是常用重音字符。
- 俄罗斯:用于表示西里尔(Cyrillic)字符。
- 希腊:表示希腊字母。
Unicode
尽管 ASCII 留有空余编码,但对非拉丁语系的国家仍不适用(比如中国和日本)。因此各国均发明了多字节编码方案,但互不兼容,由此带来新的问题——乱码(因过于常见,在日本甚至有个词 mojibake 表示这种情况)。
Unicode 于 1992 年诞生,采用统一编码方案解决乱码问题。最常见的 Unicode 是 16 位的,可表示的量级达百万,甚至有空位放 Emoji 😉。