4.3 万维网 (The World Wide Web)
万维网 (World Wide Web) 运行在互联网 (Internet) 上,两者经常混用但不是一回事。
互联网是传递数据的管道,各种程序都会用。其中传输最多数据的程序是分布在全球数百万个服务器上的万维网,可以通过浏览器进行访问。
4.3.1 超文本和超链接
万维网的最基本单位是单个页面 (page),页面中有内容,也有去往其他页面的「超链接」(hyperlinks),点击即可跳转。
在超链接出现之前,我们需要在文件系统中找到信息或是把地址输入搜索框,才能在计算机上看到另一个信息。
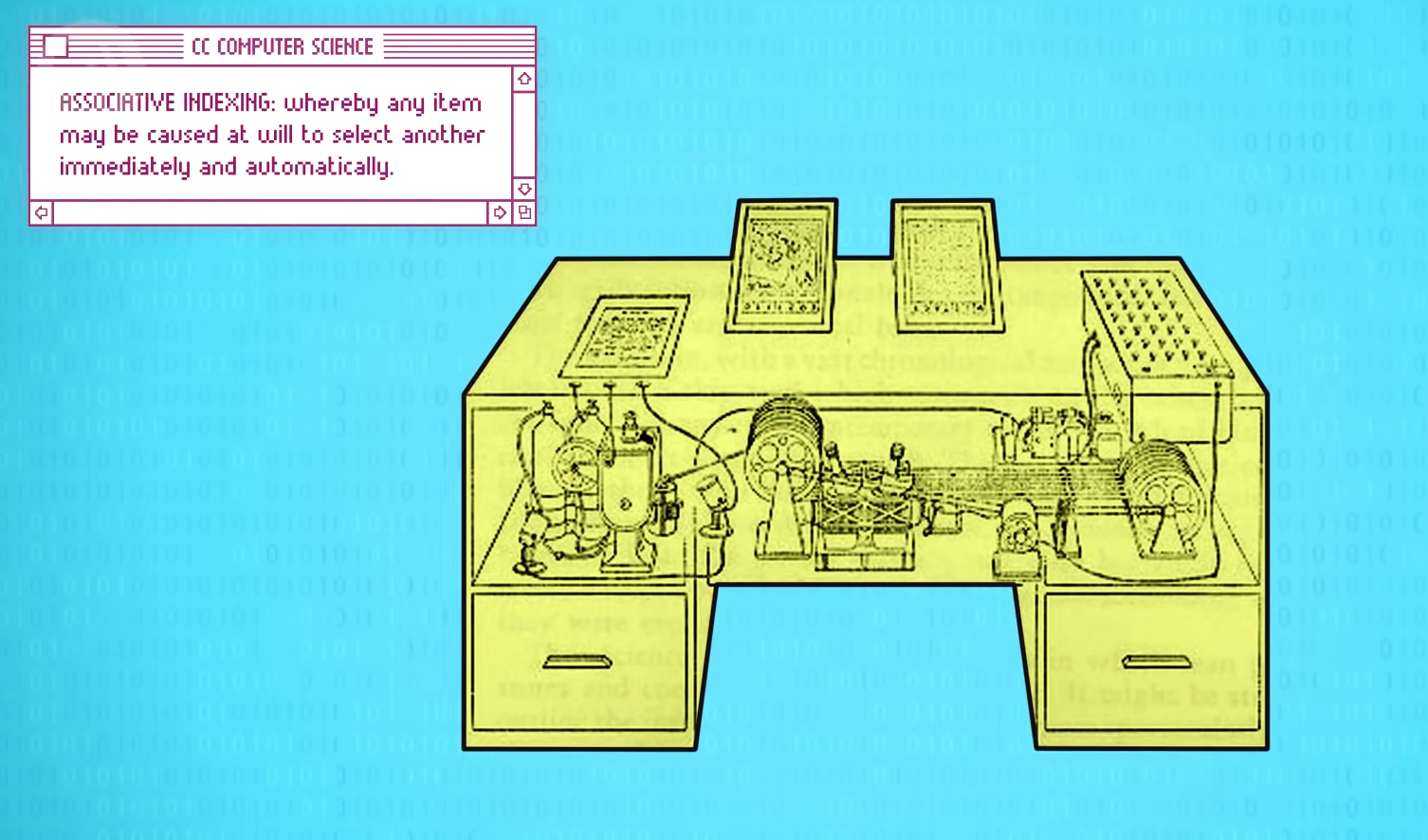
Vannevar Bush 所构想机器 Memex 对其有相关的形容:
[!quote] “关联式索引.. 选一个物品会引起另一个物品被立即选中,将两样东西联系在一起的过程十分重要。在任何时候,当其中一件东西进入视线只需点一下按钮,立马就能回忆起另一件。”
在还未出现显示屏的 1945 年,这个想法非常超前。因文字超链接的强大,它有了一个专有名词「超文本」(hypertext)。如今的超文本通常指向另一个网页,然后由浏览器进行渲染。
4.3.2 URL
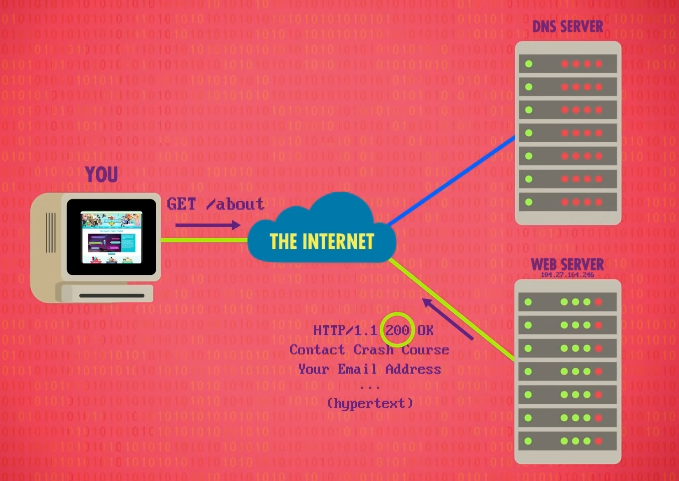
网页用于互相连接的唯一地址,称为「统一资源定位器」(Uniform Resource Locator, URL)。以访问 crash courses 的网页 thecrashcourse.com/courses 为例:
- DNS 查找:输入 thecrashcourse.com 域名,输出对应 IP 地址。
- 建立连接:浏览器请求与运行着网页服务器的 IP 地址建立起 TCP 连接,使用标准端口号 80。
- 请求服务:使用「超文本传输协议」(Hypertext Transfer Protocol, HTTP) 来向服务器发送指令 “GET /courses”,来请求名为 “courses” 的页面。
- 返回渲染:请求指令以"ASCII编码"发送到服务器后,服务器返回该地址所对应的网页,浏览器将网页渲染至屏幕上。
4.3.3 HTTP
HTTP 的第一个标准 HTTP 0.9 创建于 1991 年,只有一个 “GET” 指令。当用户在网页中点击其他超链接是,计算机会重新发送 GET 请求,浏览网页的过程就是不断重复发送 GET 请求的过程。
在之后的版本,HTTP 添加了放置在请求前的状态码 (status codes),用于指明请求状态。
200 表示 OK - 网页找到了给你,而 400~499 则代表客户端出错,比如 404 代表网页不存在。
4.3.4 HTML
因超文本的存储和发送都是以普通文本的形式进行,利用 ASCII 或 UTF-16 进行编码解释,需要通过一种标记方法来区分文本和连接,因此诞生了「超文本标记语言」(Hypertext Markup Language, HTML)。
HTML 第一版的版本号是 0.8,创建于 1990 年,有 18 种HTML指令,通常由一对开始标签和结束标签 (tag) 构成,基本指令如下:
<h1> 标题 </h1>:一级标题。<a href=链接> 文本 </a>:超链接。<ol><li>有序列表</li></ol>:无序列表。

将这些文字使用文本编辑器(记事本),另存为 “test.html” 后拖入浏览器即可打开该网页。
最新版本的 HTML 5 由 100 多种标签,包括图片标签、表格标签、表单标签、按钮标签等。
此外,还可以使用「层叠样式表」(Cascading Style Sheets, CSS) 和 JavaScript 等技术,加进网页来做一些更厉害的事。
4.3.5 浏览器
第一个浏览器和服务器是 Tim Berners-Lee 在 1990 年写的,一共花了 2 个月,同时他还建立了 URL, HTML 和 HTTP 这几个最基本的网络标准。
他在瑞士的"欧洲核子研究所"(CERN) 工作,已经研究超文本系统有十几年了。起初这个浏览器和服务器仅在 CERN 内部使用,1991 年对外发布,万维网就此诞生。

万维网带有开发标准,因此大家都可以开发新的服务器和浏览器。“伊利诺伊大学香槟分校"的一个小组在 1993 年做了 Mosaic 浏览器,这是第一个可以在文字旁边显示图片的浏览器。
此前浏览图片需要单独开启新窗口,Mosaic 还引进了书签等新功能,界面友好,使它很受欢迎。
1990 年代末有许多浏览器面世,比如 Netscape Navigator, Internet Explorer, Opera, OmniWeb, Mozilla。同时也有很多服务器面世, 比如 Apache 和 微软互联网信息服务(Microsoft’s Internet Information Services, IIS)。在这个黄金时代中,也诞生了许多网络巨头,如创始于 1990 年代中期的亚马逊和 eBay。
4.3.6 搜索引擎
门户网站
随着网页日益增多,寻找所需内容变得困难。起初人们会维护一个链接到其他网站的目录。
其中最有名的叫 “Jerry和David的万维网指南” (Jerry and David’s guide to the World Wide Web),它在 1994 年改名为 Yahoo。
随着网络越来越大,人工编辑的目录变得不便利,于是出现了「搜索引擎」(search engines)。
Jump Station
最像现代搜索引擎的最早搜索引擎是由 Jonathon Fletcher 于 1993 年在斯特林大学创建的 JumpStation,它由三部分组成:
- 爬虫 (web crawler):顺着链接不停探索的软件,看到新链接时将其加入自己的列表当中。
- 索引 (index):记录爬虫访问过的网页中,出现过哪些关键词。
- 搜索算法 (search algorithm):用于排序匹配上关键词的网页先后顺序。
早期搜索引擎的算法仅取决于搜索词在页面上的出现次数,有些内容农场会不断重复热门搜索词来吸引人们,拉低信息搜索质量。Google 创造了一个算法来规避这个问题,就此成名。
与其信任网页上的内容,不如信任其他网站链接到这个网站的"反向链接"数量,而反向链接中有信誉的网站占比越大,则可认为网站质量越高。
Google 一开始时是 1996 年斯坦福大学中名为 BackRub 的一个研究项目,两年后分离出来,演变成如今的谷歌。
4.3.7 网络中立性
网络中立性 (Net Neutrality) 是指应该平等对待所有数据包,不论它的内容是什么,其传输速度和优先级应当是一致的。
有些公司会乐意通过故意给某些数据更少带宽和更低优先级的方式,来使得自己的数据优先到达,这种方式为「节流」(Throttled) 。
支持"网络中立性"的人认为失去中立性后,服务商可以推出提速的"高级套餐”,为剥削性商业模式埋下种子,使得龙头企业拥有特权优势,而初创公司出于劣势,不利于创新。另一方面,从技术原因来看,我们也很容易希望即时通讯的消息比邮件的优先级更高、更快到达。
而反对"网络中立性"的人认为,市场竞争会阻碍不良行为。如果供应商把客户喜欢的网站降速,客户会离开供应商。